爬虫
爬虫
1. 相关概念介绍
- 解释1:通过一个程序,根据 Url 进行爬取网页,获取有用的信息
- 解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
1.1 爬虫核心?
- 爬取网页
- 解析数据(重点)
- 难点:爬虫与反爬虫之间的博弈
1.2 爬虫的用途
- 数据分析/人工数据集
- 社交软件冷启动
- 舆情监控
- 竞争对手监控
1.3 爬虫分类
- 通用爬虫(不学)
- 功能:访问网页->抓取数据->数据存储->数据除了->提供检索服务
- 实例:百度、google等搜索引擎
- 缺点:
- 抓取的数据大多是无用的
- 不能根据用户的需求来精准获取数据
- 聚焦爬虫
- 功能:根据需求,实现爬虫程序,抓取需要的数据
- 设计思路:
- 确定要爬取的url
- 模拟浏览器通过 http 协议访问 url,获取服务器返回的 html 代码
- 解析 html 字符串
- 增量式爬虫
- 检测网站中的数据更新情况,只会抓取网站中最新更新出来的数据
1.4 反爬手段
- User-Agent:
- 简称 UA,是一个特殊的字符串头,能识别客户使用的操作系统及版本、CPU 类型、浏览器语言、插件等等
- 代理 IP
- 验证码访问
- 动态加载网页
- 网站返回的是 js 数据,并不是真实的网页数据
- 数据加密
2. urllib 库使用
2.1 基本使用
python 本身自带,不需要安装
urllib.request.rulopen()模拟浏览器向服务器发送请求- response 服务器返回的数据
- response 的数据类型是 HttpResponse
- 字节–>字符串
- 解码decode
- 字符串–>字节
- 编码encode
1 | # 使用 urllib 获取百度首页的源码 |
2.2 一个类型,六个方法
- response 是 HTTPResponse 类型
- 方法
- read()
- 字节形式读取二进制 扩展:rede(5)返回前几个字节
- readline() 读取一行
- readlines() 一行一行读取 直至结束
- getcode() 获取状态吗
- geturl() 获取url
- getheaders() 获取headers
- read()
- 代码:
1 | import urllib.request |
2.3 下载
- 方法:
urlretrieve - 使用:
1 | import urllib.request |
2.4 请求对象的定制
- 爬虫是模拟浏览器向服务器发送请求的过程,定制对象(UA)是一种反爬虫的手段,需要使用headers定制操作系统
- 请求对象的定制是为了解决反爬的第一种手段
- 找到 baidu 的 UA:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69
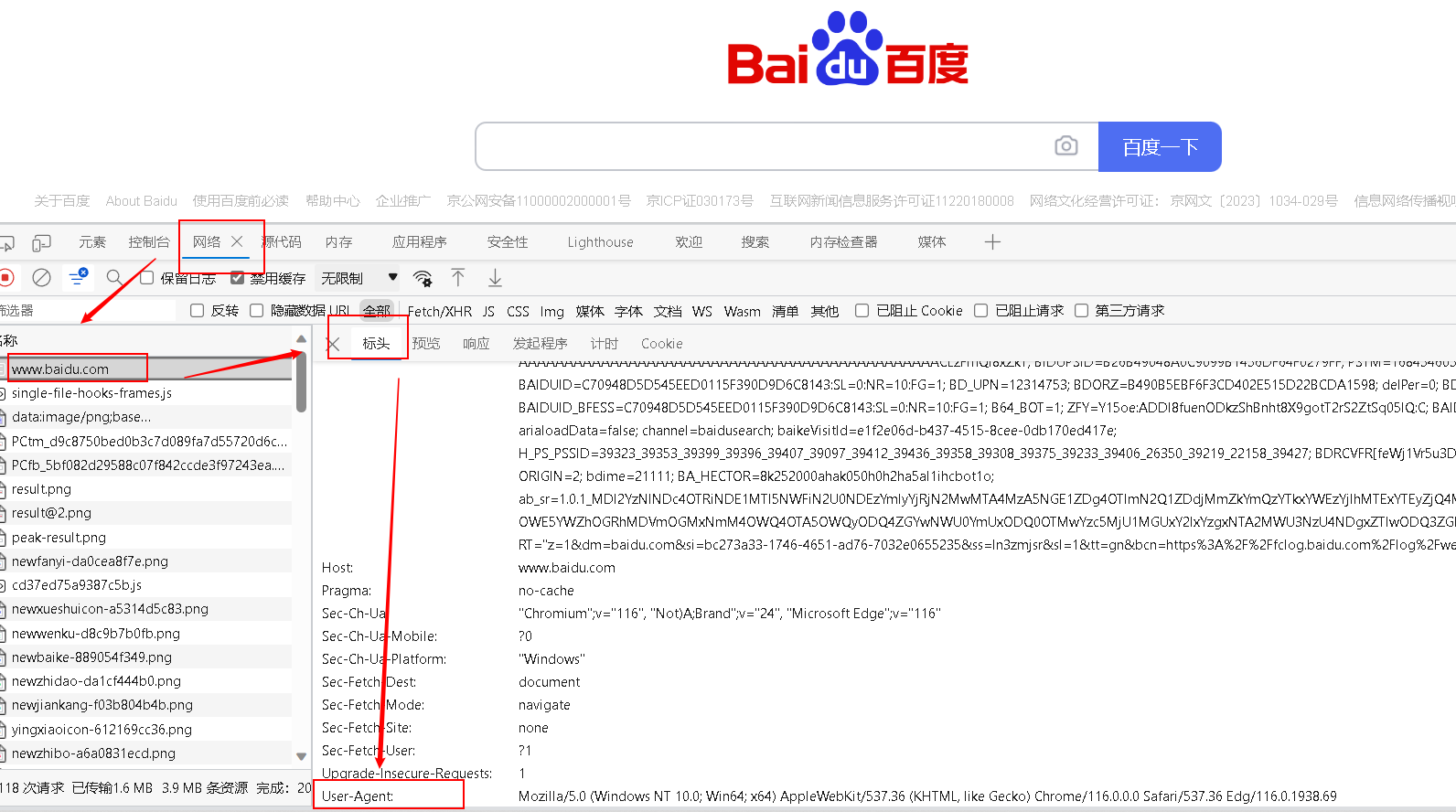
- 语法:
request = urllib.request.Request() - 代码实现:
1 | import urllib.request |
2.5 编解码
大一统编码:Unicode 编码
所以粘贴过来的url会变成这样
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6

2.5.1 get 请求的 quote 方法
把中文转换成unicode编码,不常用
- 用法:
name = urllib.parse.quote('周杰伦') - 代码:
1 | # https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 |
2.5.2 get 请求的 urlencode 方法
适用于多个参数的情况之下,直接定义为一个字典形式
1 | base_url = 'https://www.baidu.com/s?' |
2.5.3 post 请求方式
注意:post请求的参数必须进行编码,编码之后必须调用 encode 方法
data = urllib.parse.urlencode(data).encode('utf-8')POST的请求参数是不会拼接在url后面的,而是需要放在请求对象定制的参数中
难点:找谁到底是你要的那个接口
举例:百度翻译
https://fanyi.baidu.com/sug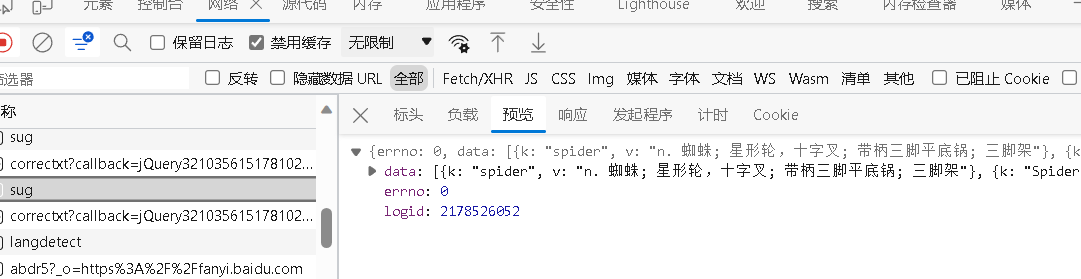
代码实例:
- 案例1:百度翻译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# post 请求百度翻译
import urllib.request
import urllib.parse
# 1. 请求地址
url = 'https://fanyi.baidu.com/sug'
# 2. 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
}
# 3. 请求参数
data = {
'kw': 'spider'
}
# post 请求的参数, 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
print(data) # kw=spider
# 4. 定制请求对象 post 的请求参数是不会拼接在 url 后面的, 而是需要放在请求对象定制的参数中
request = urllib.request.Request(url=url, data=data, headers=headers)
# 5. 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 6. 获取响应的数据
content = response.read().decode('utf-8')
print(type(content)) # <class 'str'>
print(content) # "data":[{"k":"spider","v":"n. \u8718\u86db; \u661f\u5f62\u8f6e\uff0c\u5341\u5b57\u53c9;
# 7. 字符串变成 json 对象, 这回就显示中文了
import json
obj = json.loads(content)
print(obj) # 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'},- 案例2:百度详细翻译
利用 pytharm 快速加引号,但是 url 格式注意下
1
2(.*?):(.*)
'$1':'$2',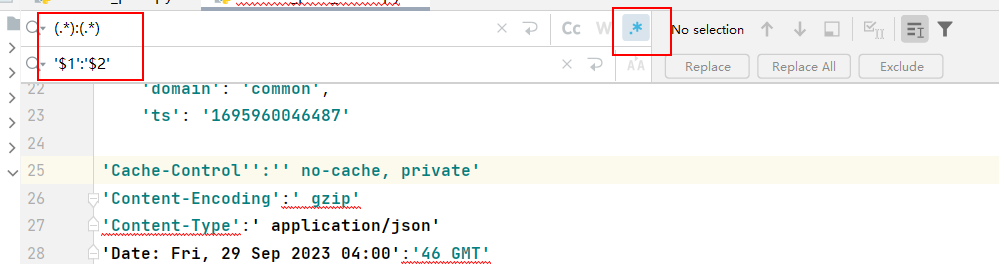

遇到反爬,起决定性因素的是请求头中的 cookie,成功:

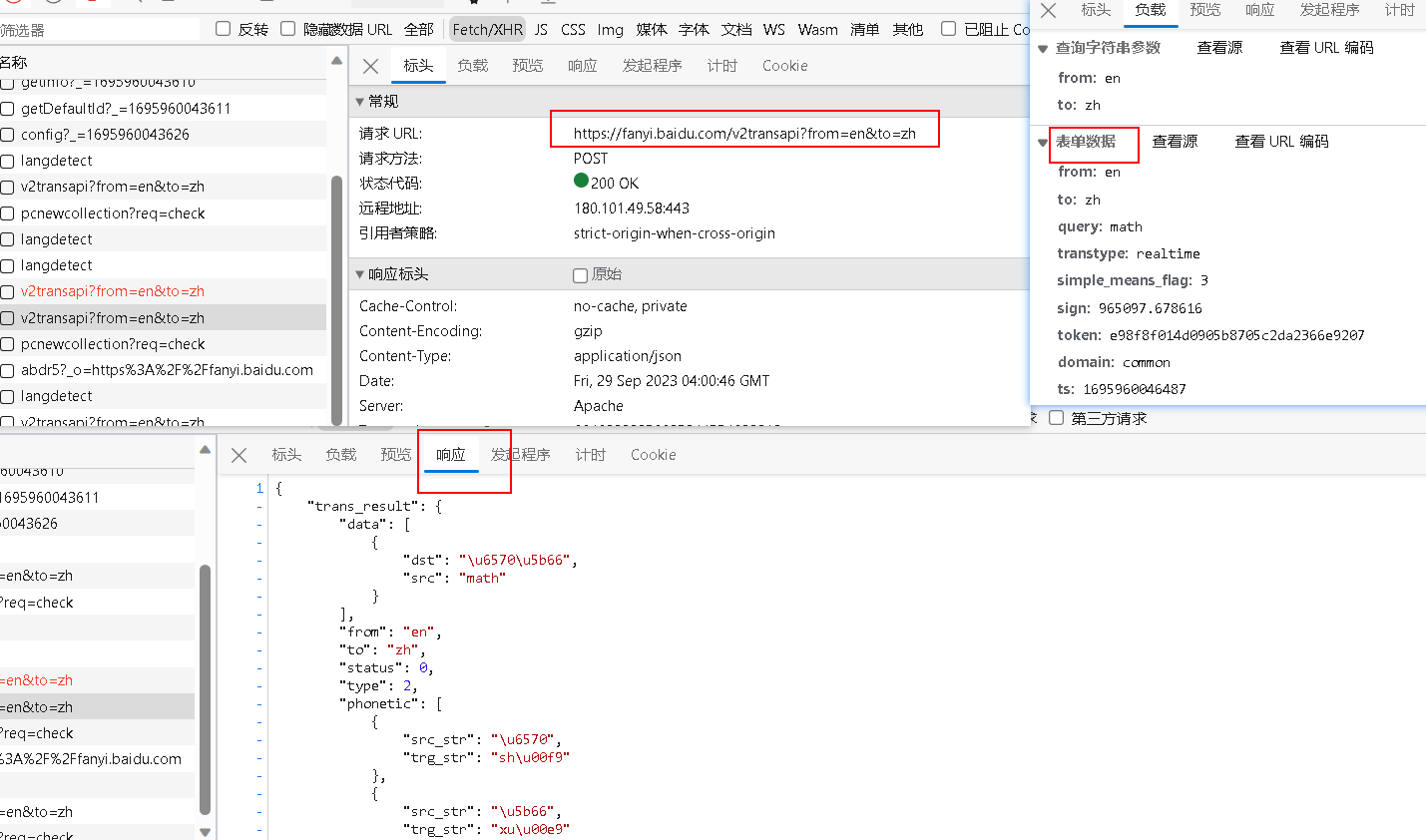
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61# 百度翻译之详细翻译 注意反爬
import urllib.request
import urllib.parse
# 1. 请求地址
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# 2. 请求头
headers = {
# 'Accept': '*/*',
# # 'Accept-Encoding': ' gzip, deflate, br', # 注释掉这句!
# 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'Acs-Token': '1695964467309_1695964468063_peDcqkvq6A8T3njv+K77v+KamobkMqSWfpCUJMKQYP/ChyN7W5OvAUIqMV/L2SbPjVfqcMkmR/Ns0/GUOysOeuMeG8t7YLflz8mpoHl1TFwSBWl3iAEg3+VU319melR/J9jHmt0EDdvCJn8EwNHDjWrd1Yis56PZXw2vUdC63L+f16WlARKCXxbTJrvQw5f1qssf+Z/itK3AReRKR+dAOnGWtvdbeU0DKt/HyfFwUKsnenFKcO0c0oMyRFi9/fnCXLy+HEaech+ZzZfB1oyInuQj9G9JJmbq2Qxx2WoOQYSQ4xiNlGNHgzJ8uGFwNLYNbJ6bxTGszkogMnHgYR1luX2o4CBhr+HddUEayDiT3CRsdNoXV4wFIQ13A8+JN1qHeSkpOz3+vGmEuSYnTObE+8CfSkkMUoMAvL/133QQDLpXDPsI1T0eEWNMBue+0EX6yahJB4MSd2iTKVXtlZtdkKHudQ0BfETC7EjMZh+MfIMSaHDV4vWeexbcc0rOI4PFWmwyoZIanp4rOr4LWg0y2d160OC2YNsG+WqsQa7YeHY=',
# 'Cache-Control': 'no-cache',
# 'Connection': 'keep-alive',
# 'Content-Length': '133',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BDUSS=E5yeFZUSFRyTUxzUEhVbXhzUkZOV3lyeDlGLUMyVWFranBDNlRiV21tTWlnRDVrSVFBQUFBJCQAAAAAAAAAAAEAAAB~ymGB06O7qGNhbzAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACLzFmQi8xZkT; BDUSS_BFESS=E5yeFZUSFRyTUxzUEhVbXhzUkZOV3lyeDlGLUMyVWFranBDNlRiV21tTWlnRDVrSVFBQUFBJCQAAAAAAAAAAAEAAAB~ymGB06O7qGNhbzAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACLzFmQi8xZkT; BIDUPSID=B26B49048A0C9099B1456DF64F0279FF; PSTM=1684546051; BAIDUID=C70948D5D545EED0115F390D9D6C8143:SL=0:NR=10:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=5; BAIDUID_BFESS=C70948D5D545EED0115F390D9D6C8143:SL=0:NR=10:FG=1; BA_HECTOR=ag01ag2g8k2hak81242k81001ihcet51p; ZFY=Y15oe:ADDl8fuenODkzShBnht8X9gotT2rS2ZtSq05IQ:C; H_PS_PSSID=39323_39353_39399_39396_39407_39097_39412_39436_39358_39308_39375_39233_39406_26350_39219_22158_39427; APPGUIDE_10_6_5=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1695958547; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1695964467; ab_sr=1.0.1_YTgxNjM4NjQ5Y2FjMmFjMjNmMjZhNDE1NjEwN2YxNmUyNTc0OGY1OGI3ZjMxOGFhMTJlNjBjMTM0NTc0YTI4OWVlNDIyZTUwZmIyNGYzZDdmYWIyZjQ3Y2Y2ZDc0YjVjMzcxM2MzMGVhNmE5OTZlYjA2ZjgyZTg4NTJhZThlYTJjZGE0MzBmYjRhZmUwMDBmYzU3NWU0YjY5YmFjYWQ1YmE1OGRkNzhiNGQ3Y2MwOWE4NTFlOTcxOTMxMjNlYzFl',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Pragma': 'no-cache',
# 'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
# 'Sec-Ch-Ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
# 'Sec-Ch-Ua-Mobile': '?0',
# 'Sec-Ch-Ua-Platform': '"Windows"',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
# 'X-Requested-With': 'XMLHttpRequest'
}
# 3. 请求参数
data = {
'from': 'en',
'to': 'zh',
'query': 'math',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '965097.678616',
'token': 'e98f8f014d0905b8705c2da2366e9207',
'domain': 'common',
'ts': '1695960046487'
}
# 编码
data = urllib.parse.urlencode(data).encode('utf-8')
# 4. 请求对象定制
request = urllib.request.Request(url, data, headers)
# 5. 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 6. 获取响应的数据
content = response.read().decode('utf-8')
print(content)
import json
obj = json.loads(content)
print(obj)
2.6 Ajax 请求
2.6.1 get 请求
案例:豆瓣电影:豆瓣电影分类排行榜 - 动作片 (douban.com)
- 先抓接口,到底谁才是第一页的数据
第一页共 20 个电影,这个接口刚好返回了 0-19 的每个电影的详细信息
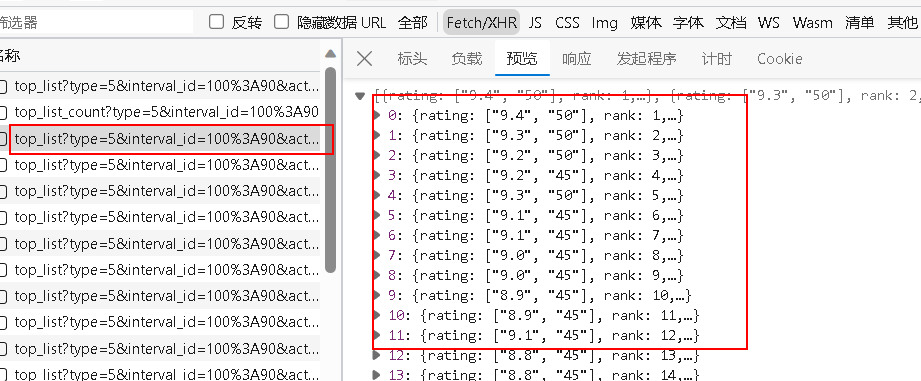
- 查看标头,发现是get请求

代码编写:
- 获取豆瓣电影第一页的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28# get 请求
# 获取豆瓣电影第一页的数据, 并且保存起来
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
}
# 1. 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 2. 获取响应数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# 3. 下载数据到本地 文件相关知识
# open 方法默认使用 gbk 编码, 要想保存中文就需要指定编码为 utf-8
fp = open('douban.json', 'w', encoding='utf-8')
fp.write(content)
# 上面两句也可这么写
# with open('douban1.json', 'w', encoding='utf-8') as fp:
# fp.write(content)- 获取豆瓣电影前十页的数据
难点:接口的寻找:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20==> 第一页https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20==> 第二页找规律,可得:
start (page-1)*201
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
# page 1 2 3 4
# start 0 20 40 60
# 规律:start (page-1)*20
# 下载豆瓣电影前10页的数据
# 1.请求对象的定制
# 2.获取响应的数据
# 3.下载数据到本地
import urllib.request
import urllib.parse
# 封装函数实现
# 1. 请求对象的定制
def creat_request(page):
# 每页的 url 不同
base_url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data) # get 请求后面就不用加 encode() 了
url = base_url + data
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
}
request = urllib.request.Request(url=url, headers=headers)
return request
# 2.获取响应的数据
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 3.下载数据到本地
def down_load(page, content):
with open('douban_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码: '))
end_page = int(input('请输入结束的页码: '))
# 遍历
for page in range(start_page, end_page + 1):
# 每一页都有自己的请求对象的定制
request = creat_request(page)
# 获取响应数据
content = get_content(request)
# 下载数据
down_load(page, content)
2.6.2 post 请求
案例:KFC 官网:肯德基餐厅信息查询 (kfc.com.cn)
- 找接口
- 请求地址:
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
- 请求地址:
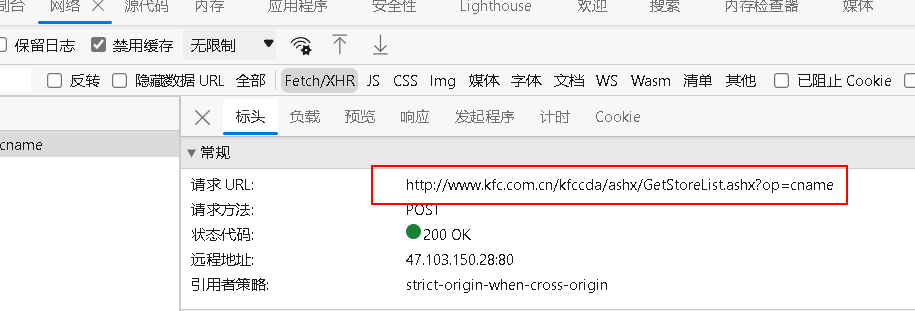
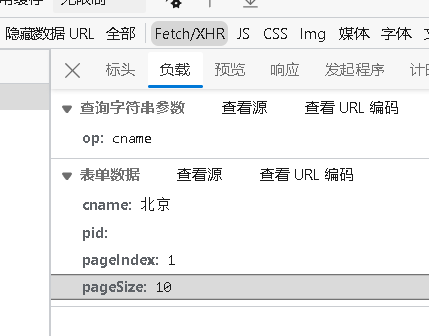
- 找请求参数
- 代码实现
1 | # 第一页 |
2.7 URLError\HTTPError
- HTTPError 类是 URLError 类的子类
- 导入的包
urllib.error.HTTPError,urllib.error.URLError - 通过 urllib 发送请求的时候又可能会发送失败,这时候若想让代码更加健壮,可以通过 try-except 进行异常捕获
- 代码示例:CSDN:
https://blog.csdn.net/qq_48108092/article/details/126097408
1 | # https://blog.csdn.net/qq_48108092/article/details/126097408 |
2.8 cookie 登录
适用场景:数据采集的时候,需要绕过登录,然后进入到某个页面
- 个人信息页面是 utf-8, 但是还是报错编码错误, 因为没有进入到个人信息页面, 而是跳转到了登陆页面,那么登录页面不是 utf-8 所以报错
- 什么情况下访问不成功?
- 因为请求头的信息不够, 所以不成功
- 如果有登录之后的 cookie, 那么我们就可以携带着 cookie 进入到登录后的任何页面
- 请求头中还有个参数
'referer': 'https://weibo.cn/'- 这个可以用于判断当前路径是不是由上一个路径进来的, 一般情况下是做图片的防盗链的
2.9 Handler 处理器
- 不能定制请求头:
urllib.request.urlopen(url) - 可以定制请求头:
urllib.request.Request(url,headers,data) - 定制更高级的请求头:Handler
- 动态 cookie 和 代理不能使用请求对象的定制
- 基本使用:
1 | # 需求: 使用 handler 访问百度, 获取网页源码 |
2.10 代理服务器
- 代理常用功能:
- 突破自身ip访问限制,访问国外站点
- 访问一些单位或团体内部资源
- 某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址免费代理服务器,就可以用于对教育网开房的各类FTP下载上传,以及各类资料查询共享等服务
- 提高访问速度
- 扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区取出信息,传给用户,以提高访问速度
- 隐藏真实ip
- 代码配置代理:
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
1 | import urllib.request |
解析
之前在urlib的学习中,我们能将网页的网页源码爬取下来。但是我们我们仅仅需要其中的部分数据,此时就需要引入新的概念——解析。
目前使用最多的解析方法包括xpath、JsonPath、BeautifulSoup等。
1. xpath
1.1 xpath 插件安装
如果是在 google 浏览器上
- 就直接将网盘里的 xpath.zip 拖到扩展程序里面

- 然后打开任意一个网页,按住快捷键
ctrl+shift+x即可出现调试工具

如果是在 edge 浏览器上,参考教程:在Edge中使用Xpath——更改快捷键_edge xpath_鹤行川.的博客-CSDN博客
由于Xpath的快捷键
Ctrl+Shift+X已经被一个叫做Web选择的功能占用(这个功能可以复制不让复制的页面内容!!震惊,才知道!),所以先下载下来修改快捷键后的 xpath 版本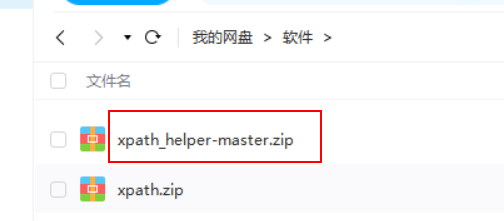
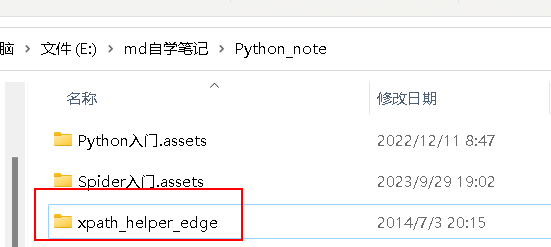
然后打开 edge 的扩展功能,同时开启开发人员模式,解压后拖入即可,使用快捷键
ctrl+alt+X即可打开调试窗口,注意插件的文件不要乱移位置
1.2 xpath 基本使用
1.2.1 lxml 库的安装
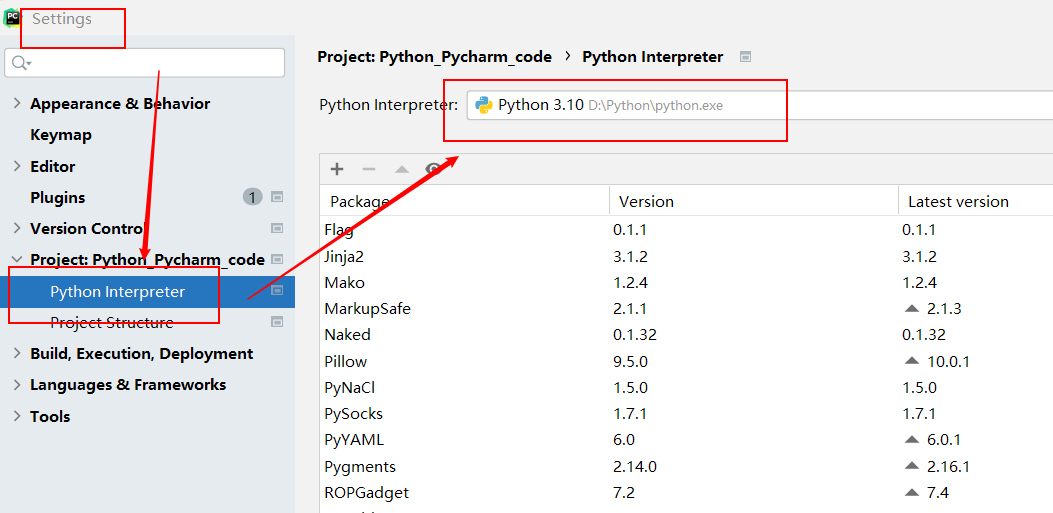
还需要安装一个库
lxml才能用:pip install lxml -i https://pypi.douban.com/simple这个库的安装路径需要在你目前项目所用的 python 解释器的目录下边
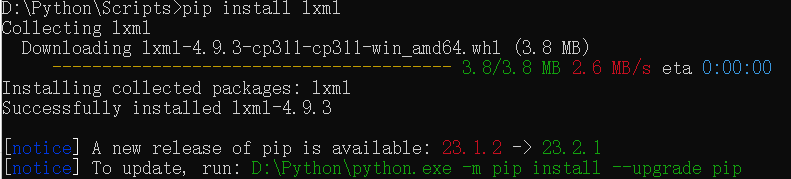
- 输入命令进行安装
1 | cd Scripts |

- 导入验证:
from lxml import etree
1.2.2 xpath 解析
- 解析什么?
- 本地文件
etree.parse('XX.html')
- 服务器响应的数据
etree.HTML(response.read().decode('utf‐8')- 实际这种情况用的多
- 本地文件
- xpath 基本语法:

1 | from lxml import etree |
1.3 获取百度页面的 百度一下 四个字
- 先获取页面的源码,找到
百度一下四个字的所在位置
<span class="s_btn_wr"><input type="submit" id="su" value="百度一下" class="bg s_btn">
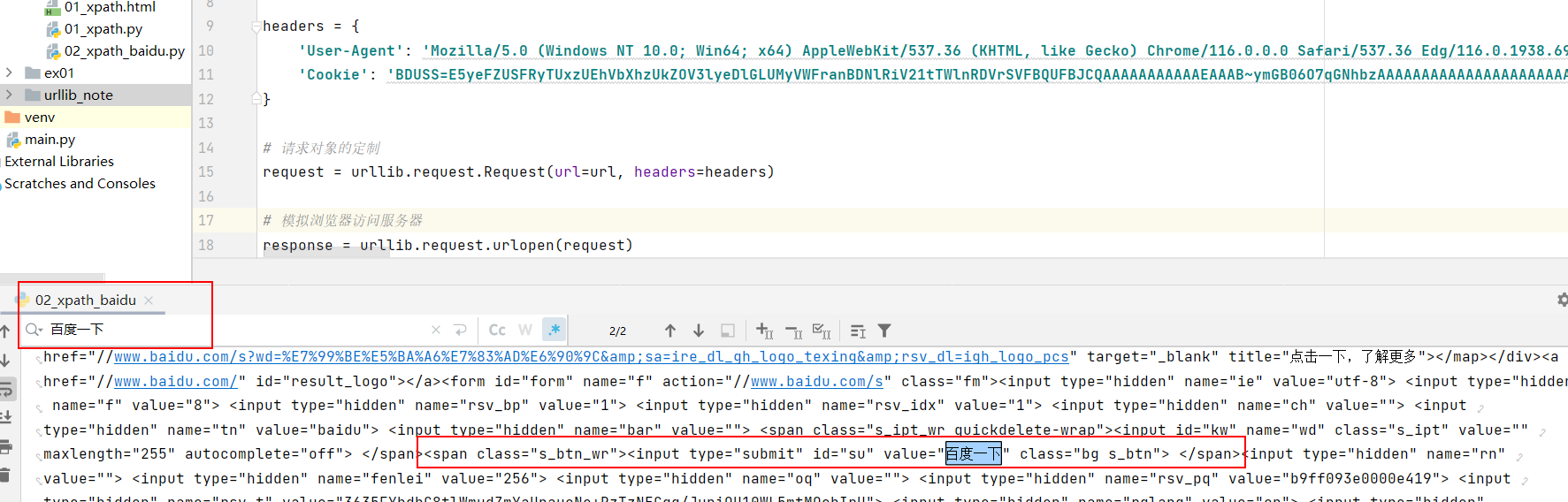
- 用xpath插件进行调试,可以找到合适的获得我们想要的数据的路径

- 代码实现:
1 | # 1. 获取网页的源码 |
1.4 站长素材(含懒加载、如何下载其中的高清图)
网址:
https://sc.chinaz.com/xpath 调试获取图片的地址和alt值,但是这里好像返回的和页面中的不太一样,最后输出的结果为空,还是直接打印出 content 之后用 ctrl+F 查找吧
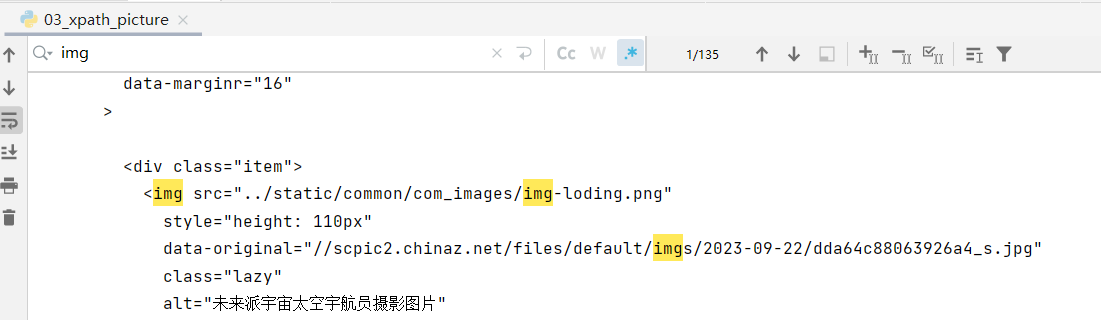
//div[@class='item masonry-brick']/img/@data-original

//div[@class='item masonry-brick']/img/@alt

- 代码实现:
1 | # 1. 请求对象的定制 |
2. JsonPath
JsonPath 适用于解析网页源码的返回值为Json数据的网站
比如打开“淘票票”:
https://dianying.taobao.com/,按F12 打开检查,点到网络。然后点击“淘票票”中的城市,会得到一个网络包,发现它是一个Json数据。后面我们将爬取该数据包存储的淘票票支持的城市
2.1 基本介绍
2.1.1 安装及使用
jsonpath 只能解析本地文件,不能解析服务器响应的文件
- pip 安装:
pip install jsonpath
- jsonpath 的使用:
- 导入
import jsonpath obj = json.load(open('json文件', 'r', encoding='utf-8'))ret = jsonpath.jsonpath(obj, 'jsonpath语法')
- 导入
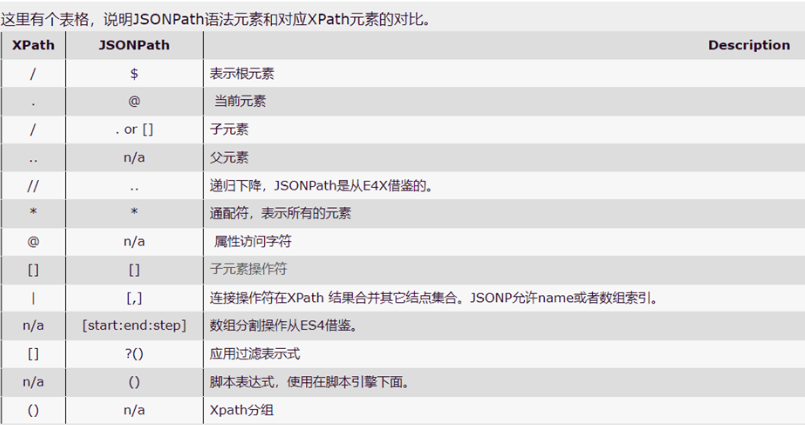
2.1.2 基本语法(与 xpath 对比)
2.1.3 基本使用
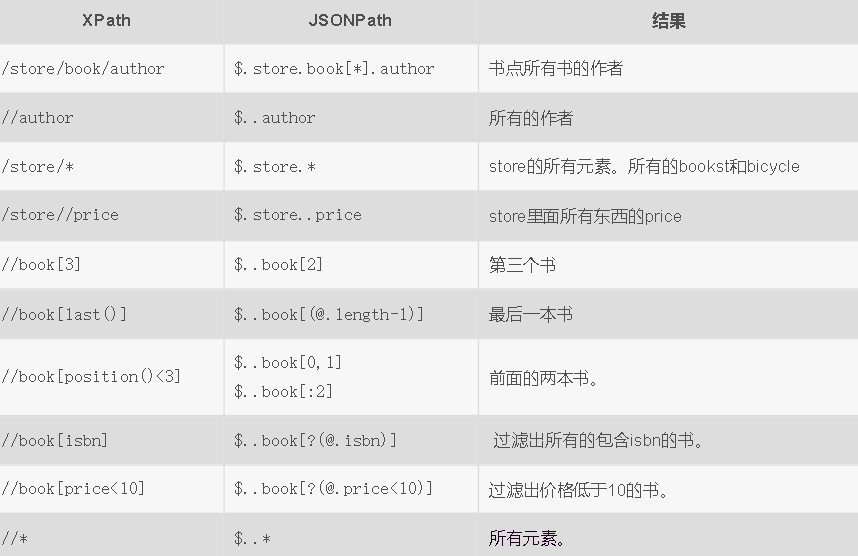
- 已知有如下的json文件
1 | { |
- 用jsonpath代码实现爬取数据:
1 | import json |
2.2 JsonPath 解析淘票票
网址:
https://dianying.taobao.com/需求:获取所有的能买票的城市信息
找接口,看下会不会有些反爬,请求地址:
https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1695987569488_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true
访问一下,发现没给我们数据,应该是做了限制,不仅仅只校验UA,待会在请求头里我们还要给它点东西

复制所有请求头,尝试下
代码实现
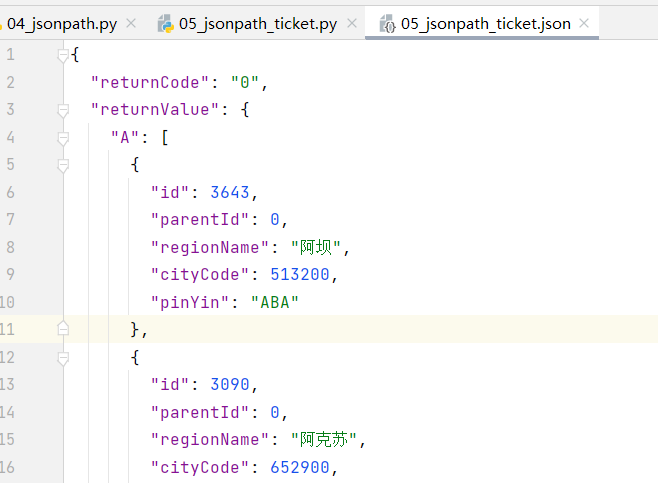
1 | import urllib.request |
- 成功获取到数据
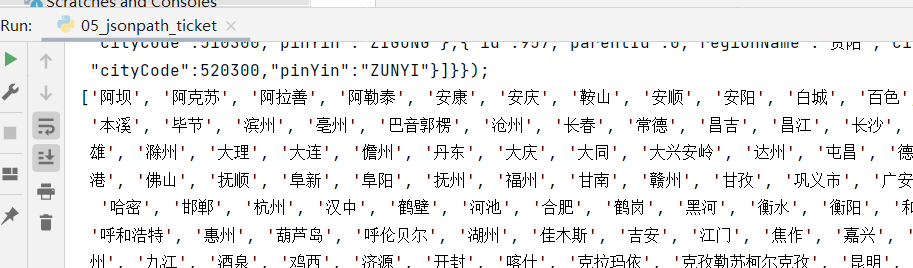
- 然后用 jsonpath 对保存到本地的json文件进行解析,筛选我们想要的所有的城市列表:
3. BeautifulSoup(即bs4)
和 xpath 是同一重量级的技术
3.1 基本使用
3.1.1 简介
和 lxml 一样,是一个 html 的解析器,主要功能也是解析和提取数据
优缺
- 缺点:效率没有 lxml 高
这缺点感觉有点不太可
- 优点:接口设计人性化,使用方便
3.1.2 安装及创建
- 安装:
pip install bs4
- 导入:
from bs4 import BeautifulSoup - 创建对象:
- 服务器响应的文件生成对象:
soup = BeautifulSoup(response.read().decode(), 'lxml') - 本地文件生成对象:
soup = BeautifulSoup(open('1.html'), 'lxml')
- 服务器响应的文件生成对象:
3.1.3 节点定位


3.1.4 节点信息

3.1.5 代码演示
- html
1 | <body> |
- py
1 | from bs4 import BeautifulSoup |
3.2 bs4 爬取星巴克数据
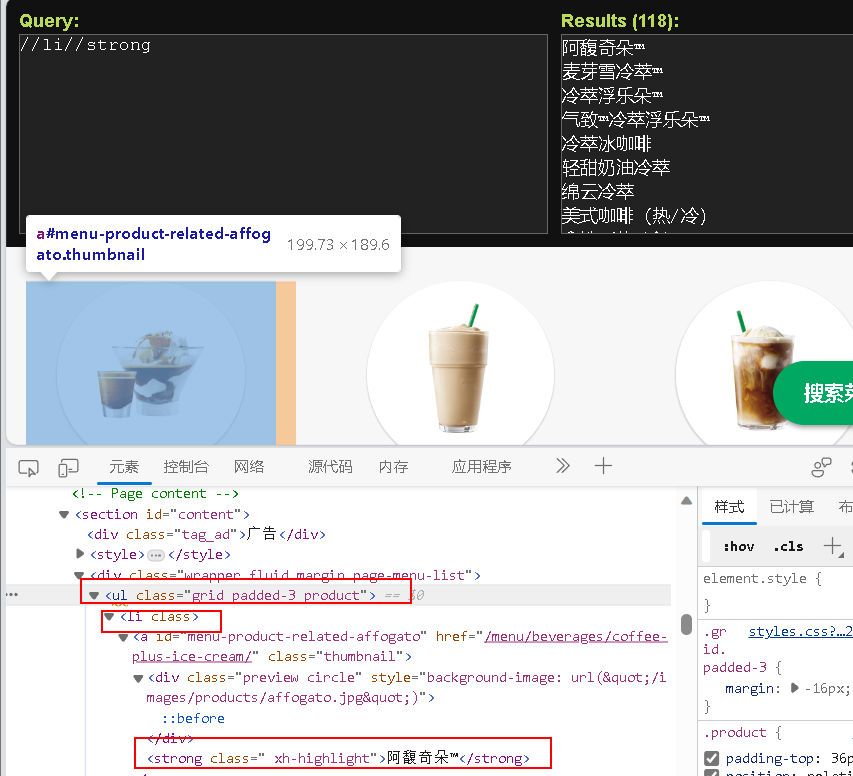
主要学习如何抓取服务器响应的文件
把菜单部分的图片以及产品的名字抓取并保存:
https://www.starbucks.com.cn/menu/
抓接口,看下只有一页,比较容易,找到接口:
https://www.starbucks.com.cn/menu/

- 先写 xpath 语法,再改成 bs4
- 抓取图片有点难,需要分析并拼接url

- 代码示例:
1 | import urllib.request |
Selenium
中文意思:[化学]硒
1. Selenium
1.1 介绍
- 什么是 Selenium
- 是一个用于 Web 应用程序测试的工具
- 其测试直接运行在浏览器中,就像真正的用户在操作一样
- 支持通过各种 driver 驱动真实浏览器完成测试
- 也支持无界面浏览器操作
- 为什么使用 selenium
- 模拟浏览器功能,自动执行网页中的js代码,实现动态加载
- 缺点:原生selenium有点慢,之后加东西使它效率变快
- 代码演示:
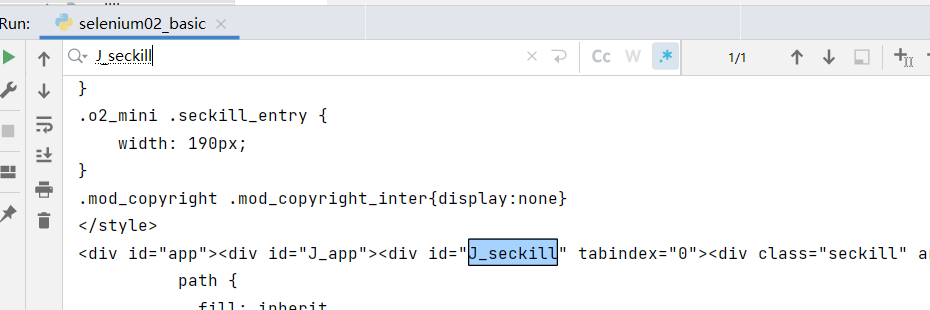
本次将要演示urllib获取京东的网页源码,从而说明使用的urllib获取京东的网页源码会缺失秒杀的一些数据,进而引入下一节将要使用的selenium
1 | import urllib.request |

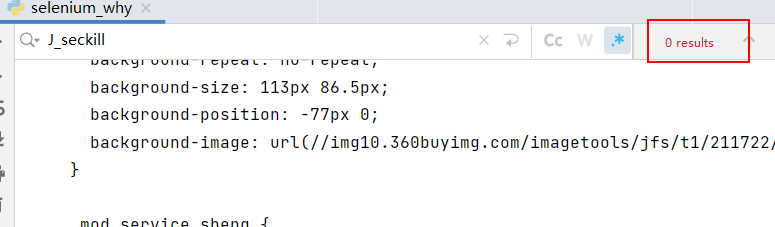
使用的urllib获取京东的网页源码,搜索秒杀中的数据,发现确实是少了秒杀的内容,因此,下一节将学习并说明selenium能驱动真实浏览器去获取数据,不会缺少内容
1.2 基本使用
1.2.1 安装 selenium
谷歌浏览器:
驱动地址下载:
http://chromedriver.storage.googleapis.com/index.html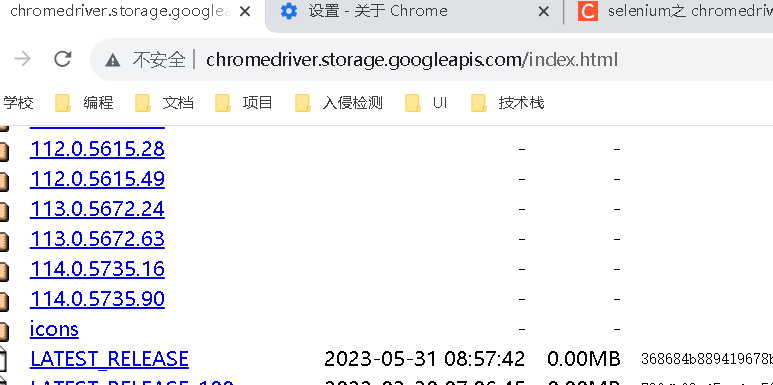
谷歌驱动和谷歌浏览器版本之间的映射表:
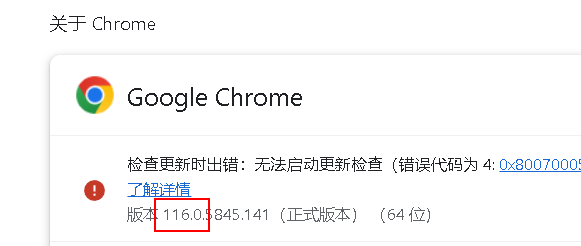
http://blog.csdn.net/huilan_same/article/details/51896672查看谷歌浏览器版本:谷歌浏览器右上角–>帮助–>关于
貌似最高才 114,我这 116 的它还没有,暂时放弃
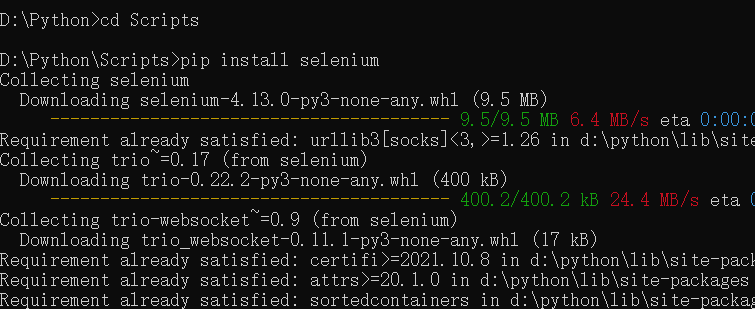
pip install selenium
使用 Edge 浏览器
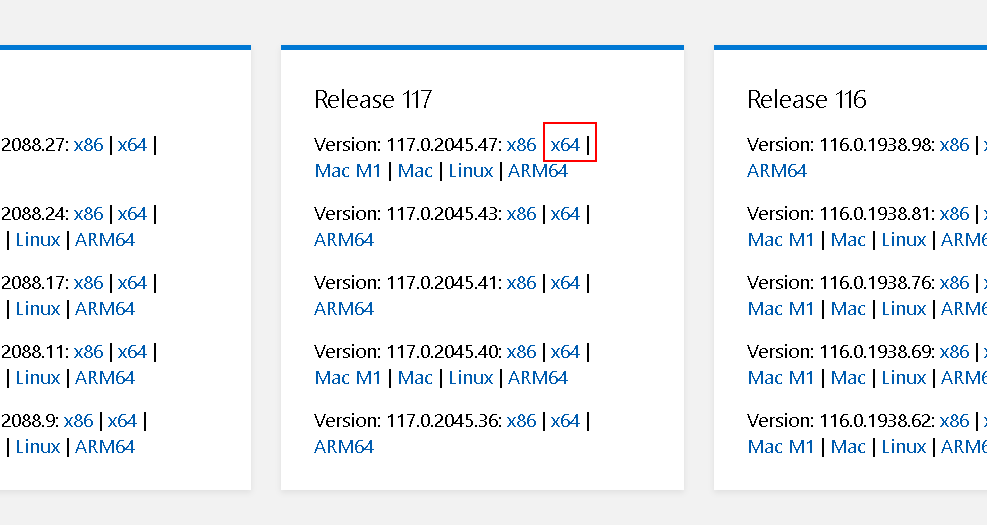
同理,先看浏览器版本号(帮助与反馈->关于),再去
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/中下载
解压文件:
- 放在代码目录下并安装:
注意selenium版本和urllib3版本不兼容的问题!
弹幕大佬建议:在selenium后面加个==3.141.0,否则后面会因为下载的selenium版本过高操作不同,个人认为高版本不好用,用法还得自己找

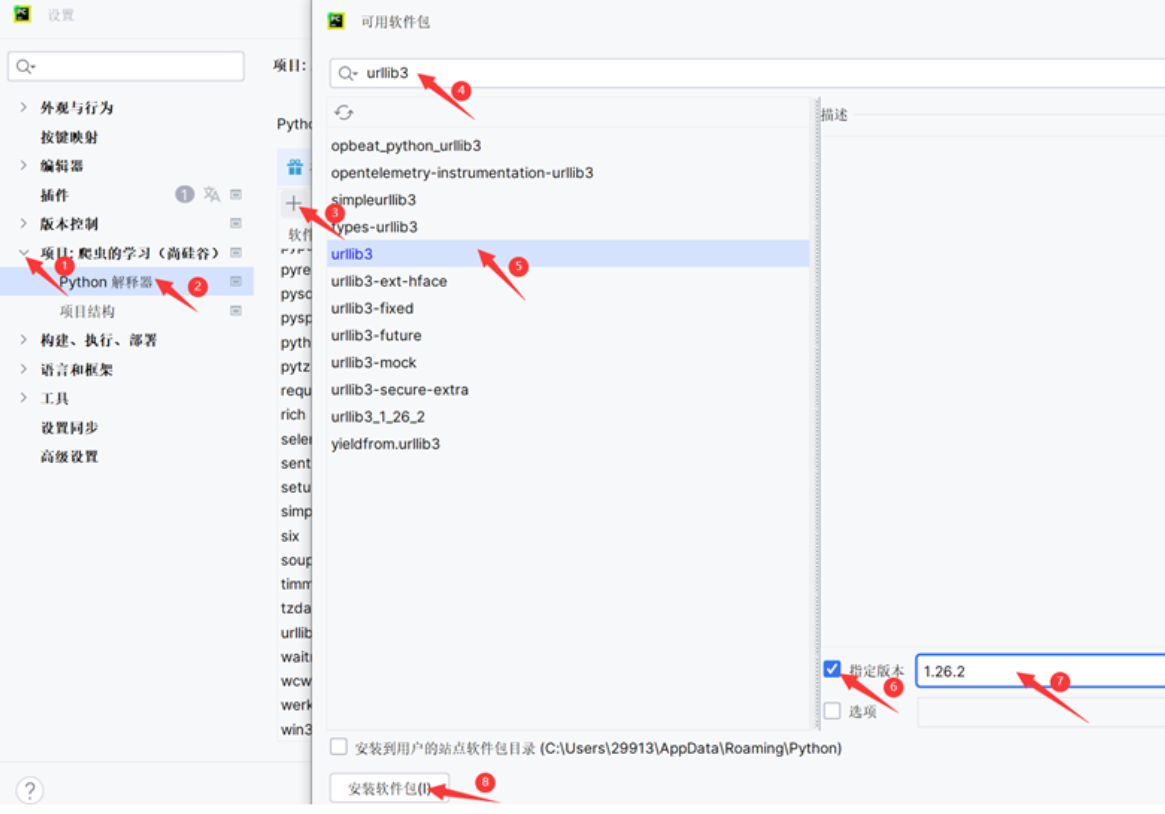
1.2.2 版本兼容问题解决
- 由于版本不兼容的问题,这里还需要改下,我改了两个位置
- selenium 改成 3.141.0 版本
- urllib3 改成 1.2.6.2 版本
- 修改参考如下步骤:
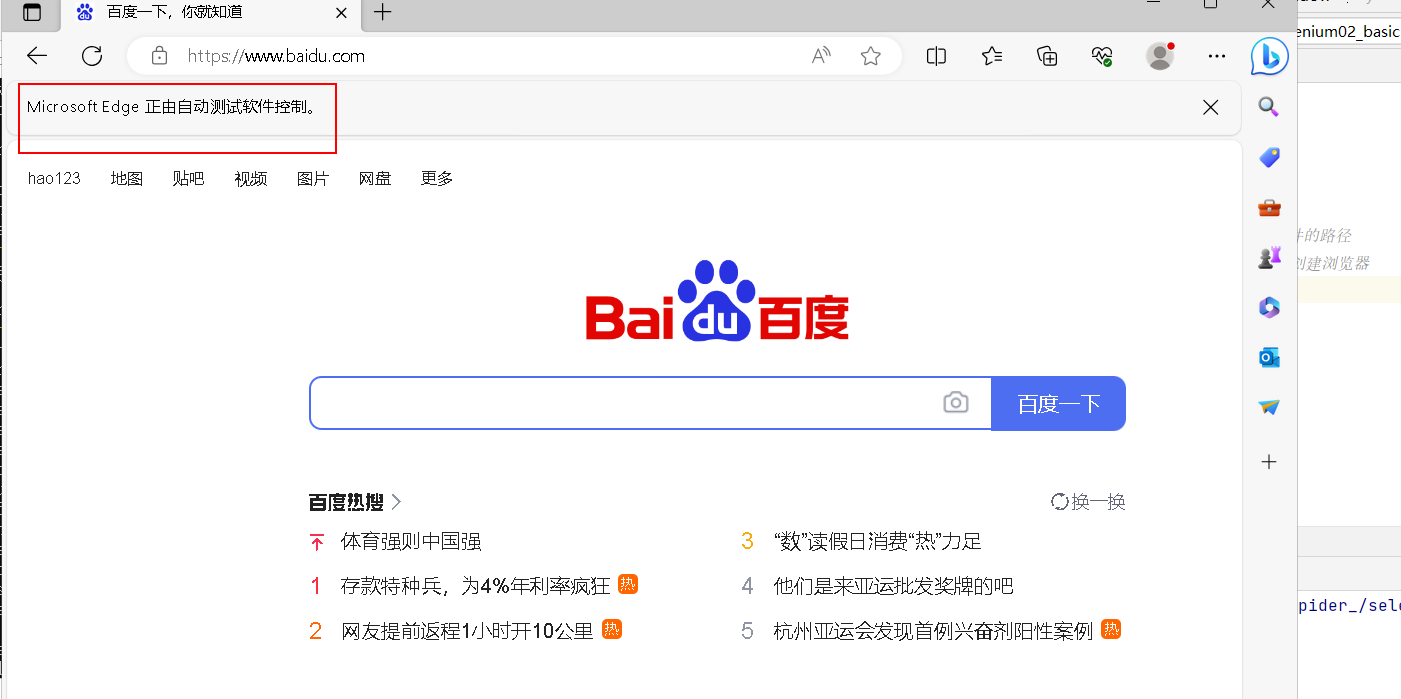
1.2.3 代码演示
- 访问百度:
1 | # 1. 导入 selenium |
- 访问京东并获取带有秒杀界面的源码
1 | # 1. 导入 selenium |
1.3 元素定位
如果我们需要使用程序在百度(
https://www.baidu.com/)中输入“周杰伦”,然后点击“百度一下”,会跳到一个新的页面。其中,使用程序找到“百度一下”的过程称为元素定位
1.3.1 元素定位的定义与方法

1.3.2 代码演示
不过这是老版本的,新版本好像把这些都结合成一个方法了
1 | from selenium import webdriver |
1.4 元素信息
1.4.1 访问元素信息
- 获取元素属性:
.get_attribute('class') - 获取元素文本:
text - 获取标签名:
tag_name
1.4.2 代码演示
1 | from selenium import webdriver |
1.5 selenium 的交互
1.5.1 交互
- 点击:
click() - 输入:
send_keys() - 后退操作:
browser.back() - 前进操作:
browser.forword() - 模拟JS滚动:
js='document.documentElement.scrollTop=100000'browser.execute_script(js) - 执行js代a码 获取网页代码:
page_source - 退出:
browser.quit()
1.5.2 代码演示
本次需要通过程序使浏览器使用百度搜索“周杰伦”,然后点到第2页,再使用一下后退、前进操作,然后再滚动到页末
1 | from selenium import webdriver |
2. Phantomjs
在前面的学习中,发现Selenium,每次执行过程中都需打开浏览器、关闭浏览器、中间还有一堆操作,这是因为它有页面,而页面里面会有js、css等等很多文件,因此打开页面会导致代码的性能很慢
因此提出Phantomjs、Chrome handless,目前Phantomjs已逐渐淘汰,这里就不学了我
2.1 介绍
- 是一个无界面浏览器
- 支持页面元素查找,js 的执行等
- 由于不进行 css 和 gui 渲染,运行效率比真实的浏览器要快的多
2.2 如何使用 Phantomjs
- 获取Phantomjs.exe文件路径path
- browser= webdriver.PhantomJs(path)
- browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot(‘baidu.png’)
3. Chrome handless
- 基本配置:
1 | from selenium import webdriver # 导入selenium库 |
requests
只属于 python?其他编程语言没有?
1. 基本使用
文档
- 官方文档:
https://requests.readthedocs.io/projects/cn/zh_CN/latest - 快速上手
https://requests.readthedocs.io/projects/cn/zh_CN/latest/user/quickstart.html
- 官方文档:
安装
pip install requests
response 的属性以及类型
| 类型 | models.Response |
|---|---|
| r.text | 获取网站源码 |
| r.encoding | 访问或定制编码方式 |
| r.url | 获取请求的url |
| r.content | 响应的字节类型 |
| r.status_code | 响应的状态码 |
| r.headers | 响应的头信息 |
- 代码示例:
1 | import requests |
2. get 请求
- 总结:
- 参数使用 params 传递
- 参数无需 urlencode 编码
- 不需要请求对象的定制
- 请求资源路径中的
?可以加也可以不加
- 代码示例:
1 | # urllib VS requests |
3. post 请求
- 抓取百度翻译
https://fanyi.baidu.com/sug
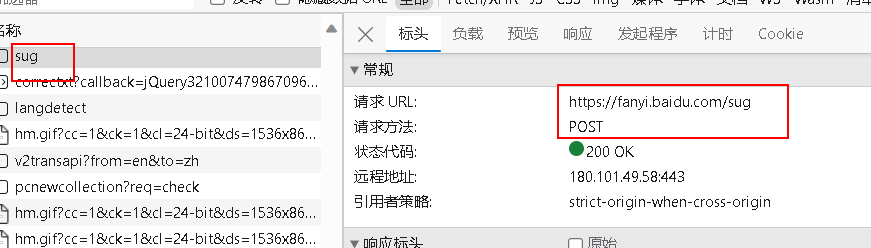
- 代码实现
1 | import requests |
- 总结:
- post请求 是不需要编解码
- post请求的参数是data
- 不需要请求对象的定制
4. 代理
1 | # 设置其他ip |
5. cookie 定制
1 | """ |
scrapy
1. srcapy 安装
1.1 什么是 srcapy
- scray 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。
- 什么是结构性数据?
- 结构性就是类似的具有相同特征的东西,里面的数据就是结构性数据。
- 选中一本书进行定位(即在某本书处打开检查),发现这些书的信息有一个相同的结构,比如书名都在结构“/html/body/div[6]/div/div[2]/div[2]/ul/li/div/h3/a”下,它们具有相同的结构,这就是结构性的例子。至于结构性数据,比如书名就是该结构下的数据。
- 优点
- 爬取速度快
- 代码简单好用
1.2 srcapy 的安装
- 安装命令:
pip install scrapy
2. 基本使用
- 使用步骤
1 | 1. 创建爬虫的项目 |
- 代码演示
补充知识
- ajax 技术可以实现动态页面局部刷新,文件类型一般为xhr或fetch

- 如果直接访问页面url,请求获取的静态页面缺少一些的局部数据,可以考虑所抓取的数据并不是通过 url 请求到的,可能是由 ajax 动态加载请求到的,可以进行下列方式验证:
1. 模拟登录
爬取基于某些用户的用户信息
cookie:用来让服务器端记录客户端的相关状态
- 不建议用手动cookie处理,即:通过f12里的抓包工具获取cookie值,将该值封装到 headers 中
1
2
3headers = {
'Cookie': 'xxx'
}- 自动处理
- cookie 值的来源?===> 去页面抓包,找到响应头信息中包含
Set-Cookie字段的请求 - session 的会话对象:可以进行请求的发送;如果请求过程中产生了 cookie,则该 cookie 会被自动存储/携带在该 session 对象中;那么之后就可以用这个已经存储了cookie的session对象发起请求
- cookie 值的来源?===> 去页面抓包,找到响应头信息中包含
自动处理 cookie 进行模拟登录的流程:
- 创建一个 session 对象:
requests.Session() - 使用 session 对象进行模拟登录 post 请求的发送(cookie 就会被存储在session中)
- session对象对个人主页对应的get请求进行发送(携带了 cookie)
- 创建一个 session 对象:
2. sign 反爬-js 逆向
- 断点方式:
- xhr 断点 发包位置 加密参数之后断点
- 对通用参数进行处理 往上找加密点
- dom 断点 执行某一个事件 加密参数之前断点
- 往下找加密点
- xhr 断点 发包位置 加密参数之后断点
- 网页加密
3. 浏览器调试 Dev Tools
开发常用浏览器 Chrom,firefox
这里主要介绍 Chrom
3.1 各个 Tab 介绍
- 打开 Dev Tool
- 菜单>更多工具>开发者工具
- 快捷键:F12
- 打开命令菜单:
ctrl+shift+P - 常用的 Tab
- Element
- Console
- Source
- Network
- Application
3.2 控制台(Console)
- 快捷键:
ctrl + Shift + J - 控制台输入:
$_可以返回上一条语句的执行结果
$0可以返回上一个选择的DOM节点,以此类推,$1就是上一个,$2就是上上一个
3.3 JS 调试
- 在 js 代码的某一行写上
debugger,回到页面运行时就会暂停在那行
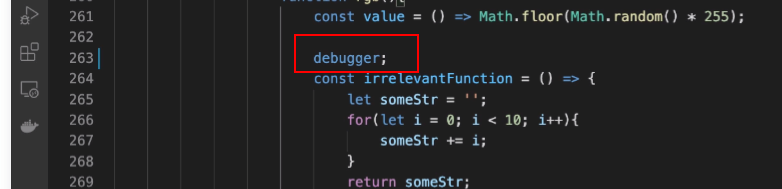
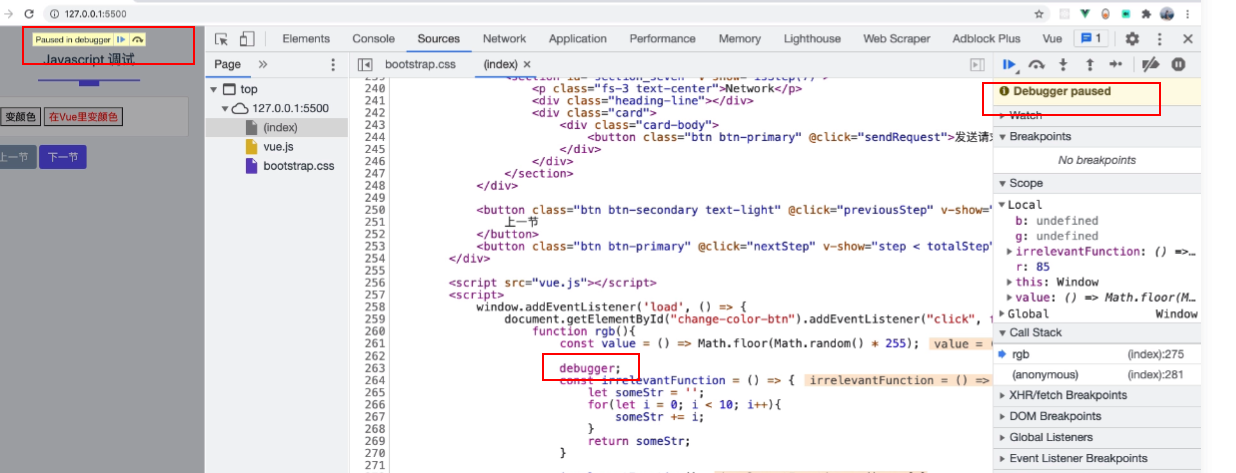
- 也可以直接点行号进行调试
- 右侧 watch 部分还可以监测某一个变量
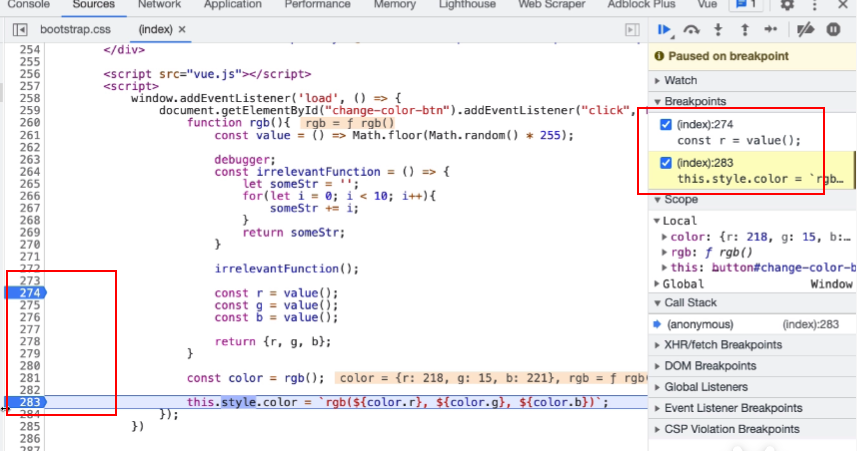
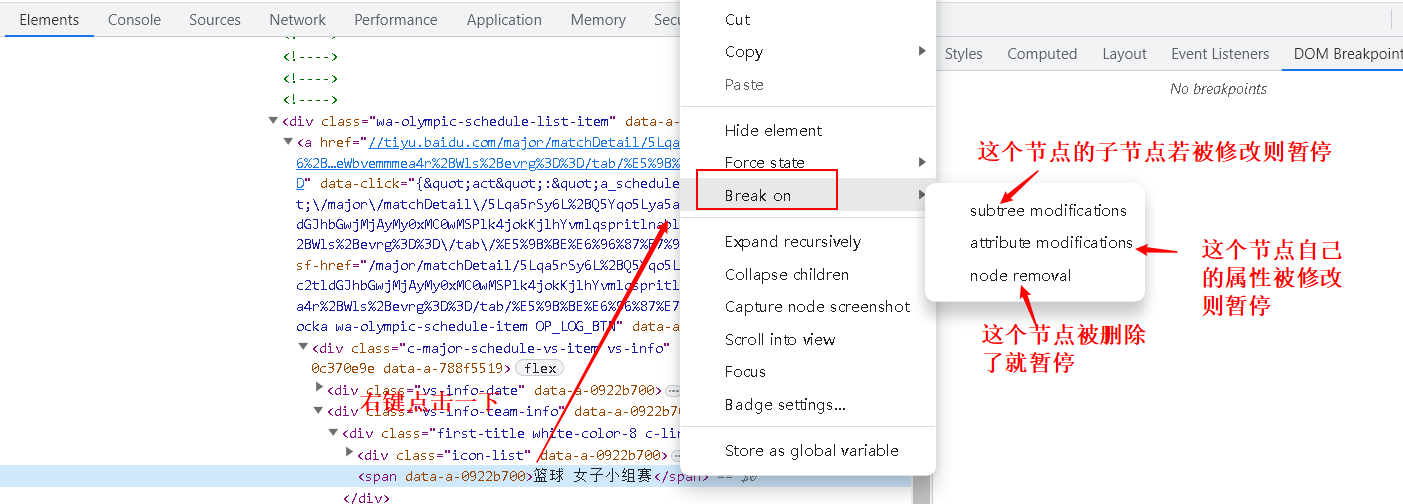
- 其他加断点方式
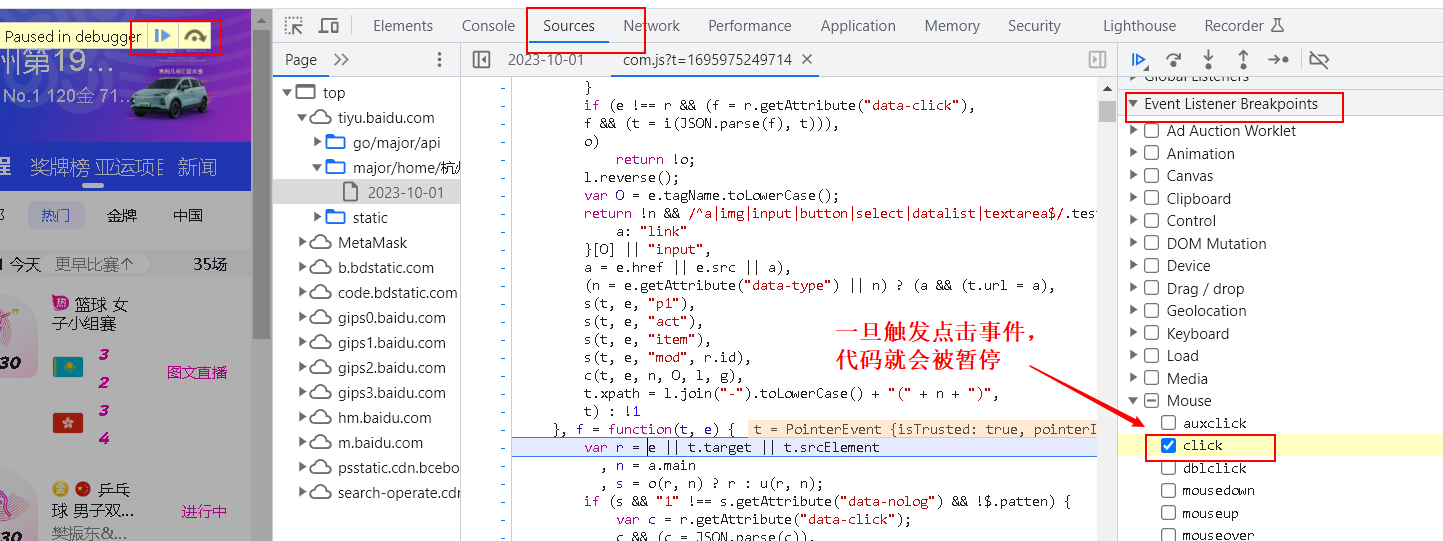
3.4 Network
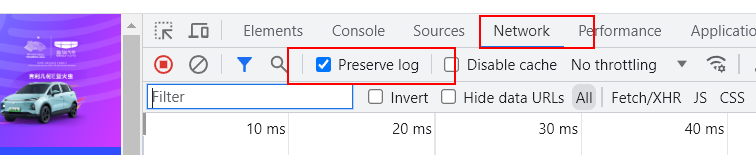
- 记住跳转页面前的上一个页面的请求,需要勾选
Preserve log
4. 案例:抓取网易云评论
这个案例很完整,建议好好学!
3 5 综合训练 抓取网易云音乐评论信息(6)_哔哩哔哩_bilibili
https://music.163.com/#/song?id=1325905146
4.1 分析接口
- 在f12抓包工具里的 XHR 选项下,可以找到获取评论的 post 接口:
https://music.163.com/weapi/comment/resource/comments/get?csrf_token=
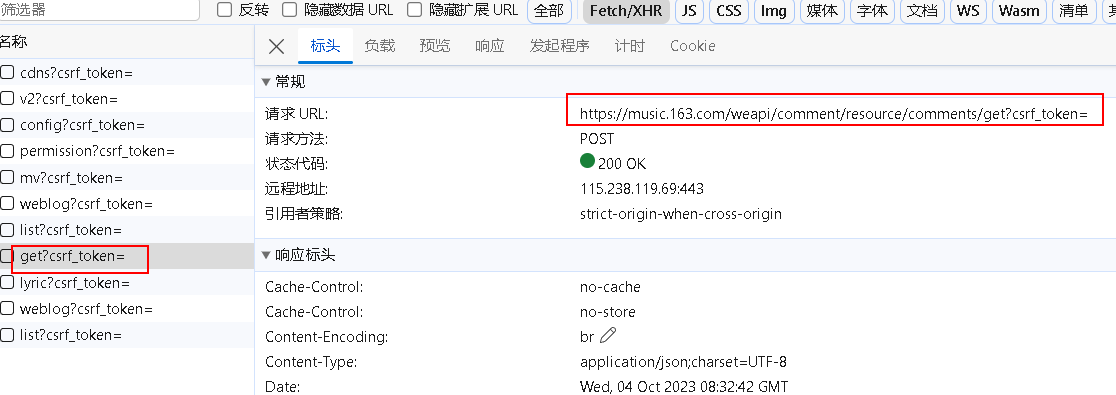
- 可以看到需要有两个参数,但都是加密的
我们需要找到其 没加密之前是咋样的?加密的过程是咋样的?最后在程序里模拟其加密过程,加密完后再请求

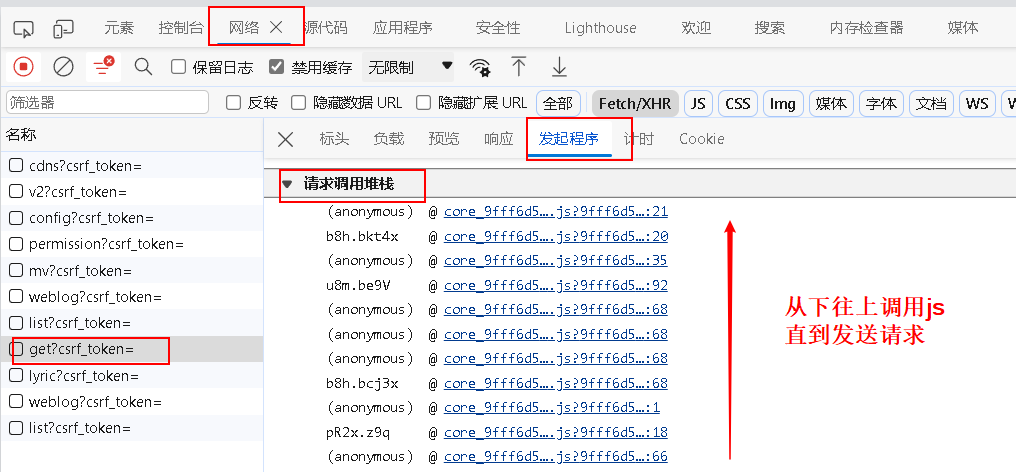
- 在
发起程序选项卡下有个请求调用堆栈,可以在这里查看所调用的 js:
4.2 逆向 js
- 尝试点击最上面的 js,也就是最后一次调用的 js,然后对代码进行分析
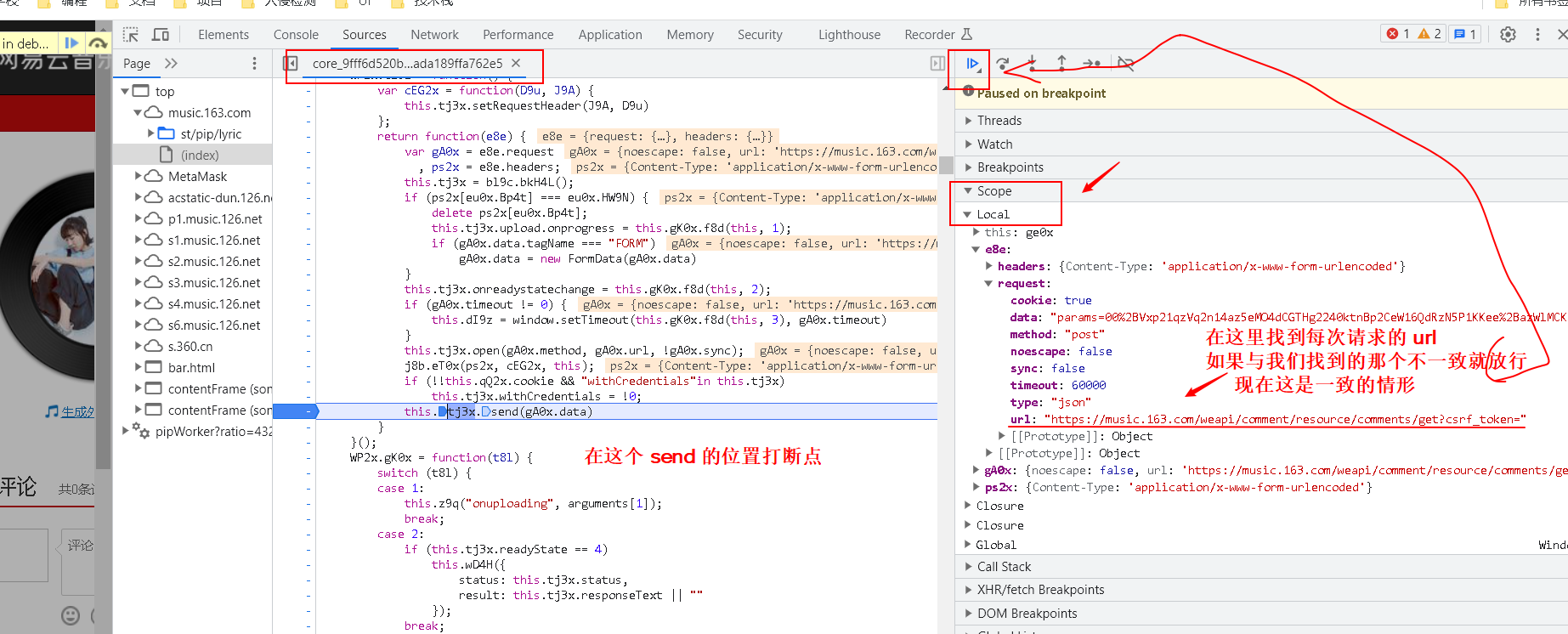
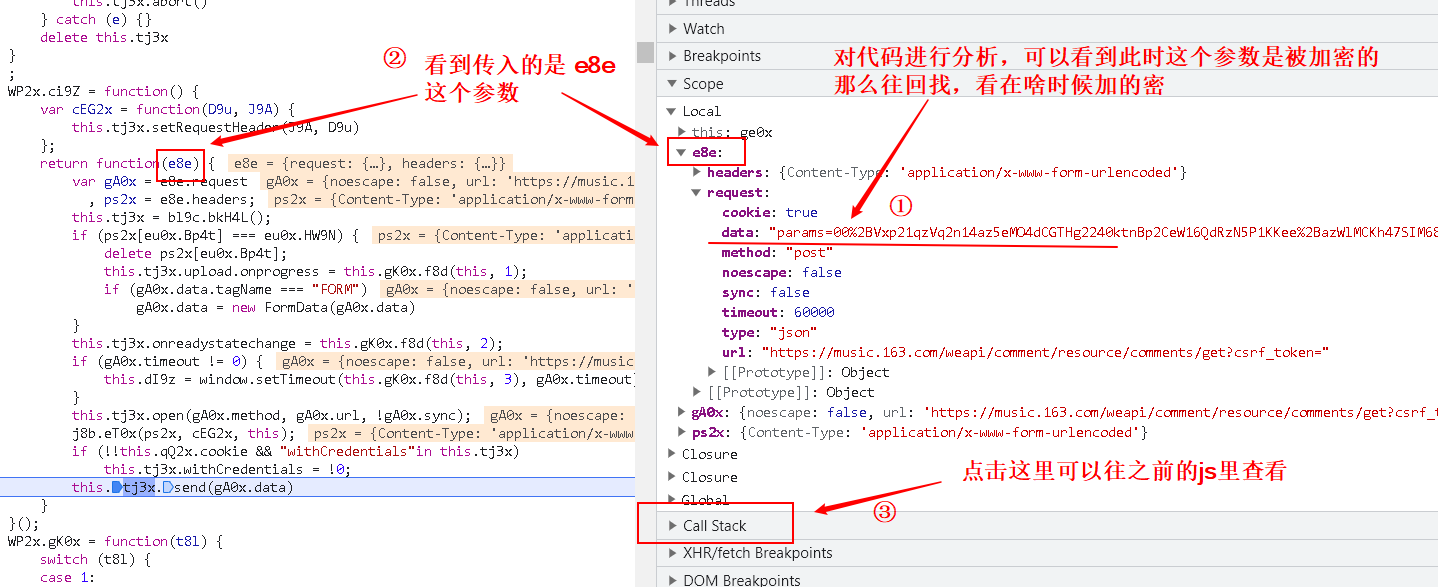
- 找到加密的js,回去对其进行分析
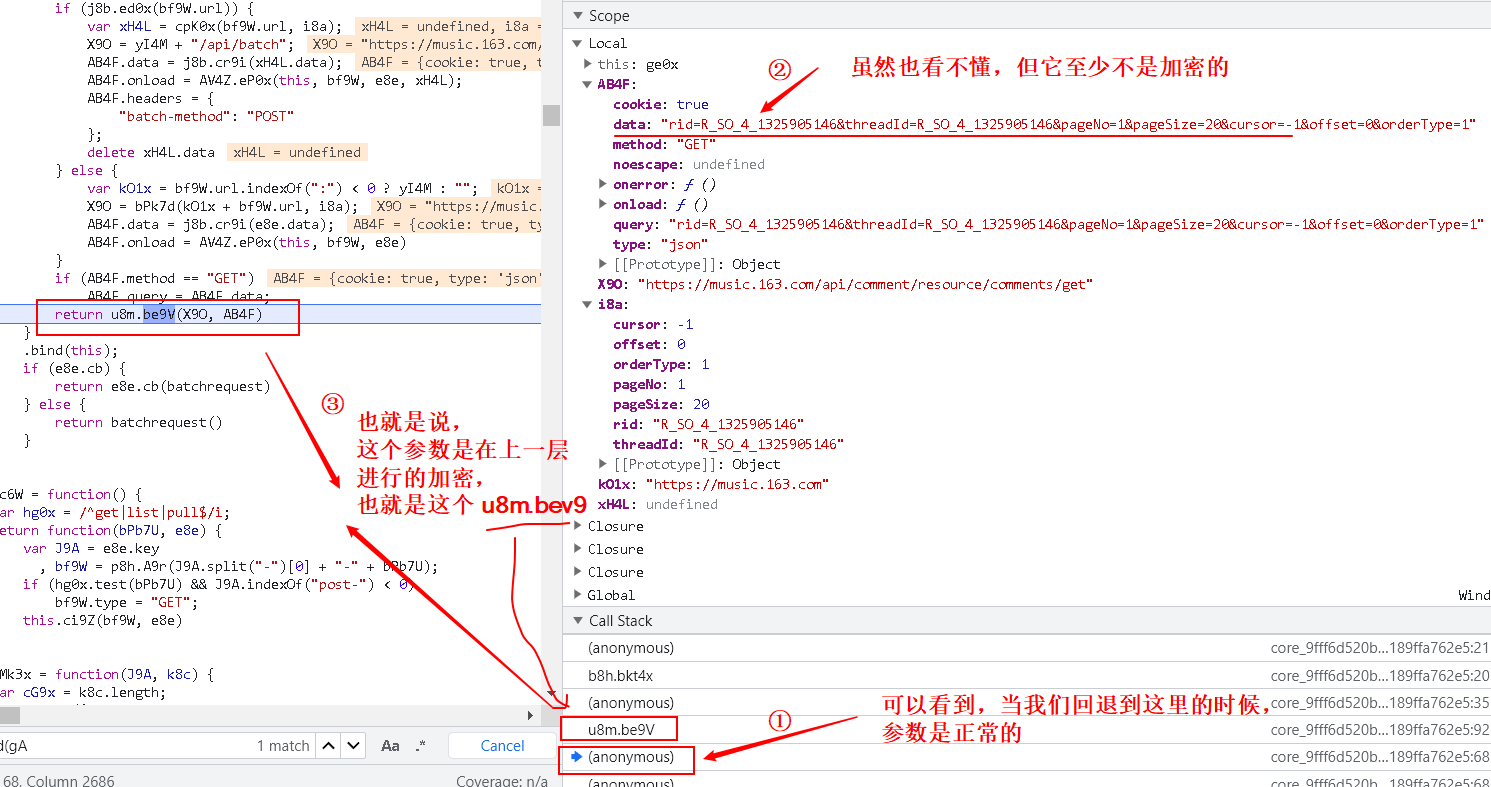
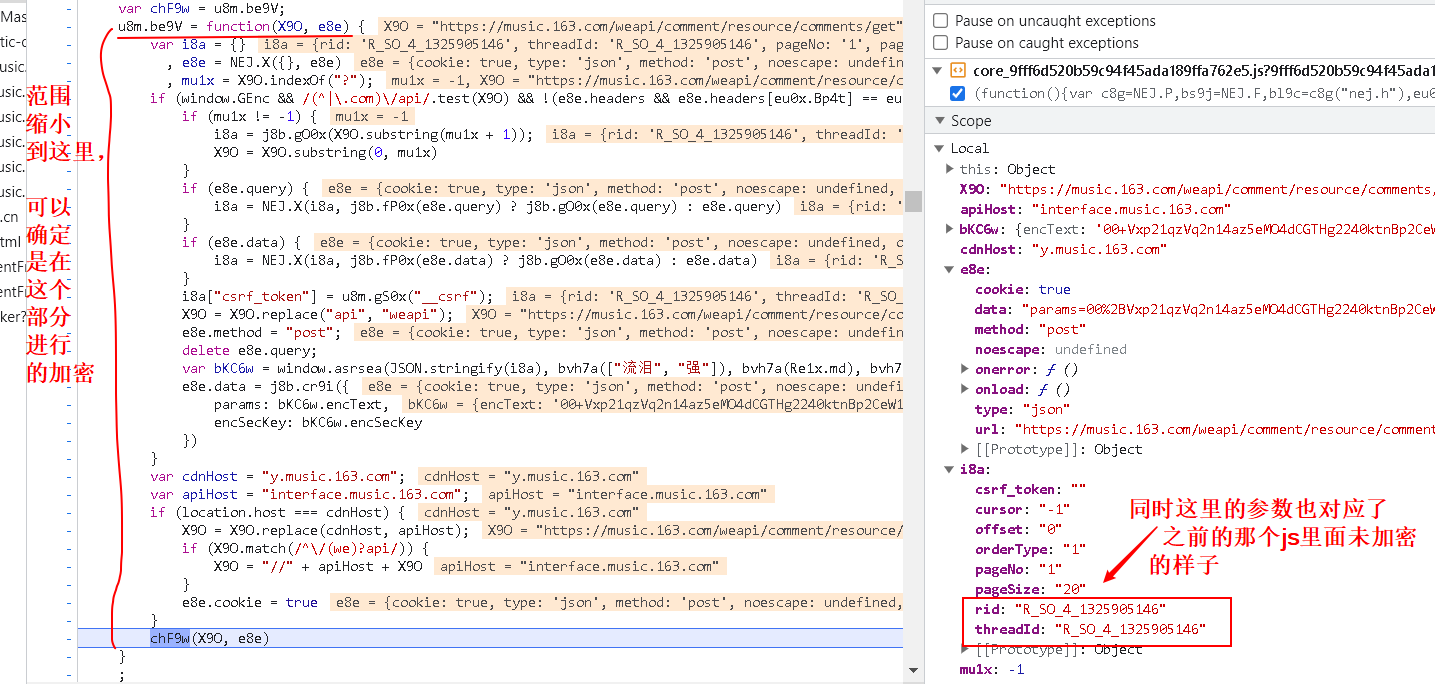
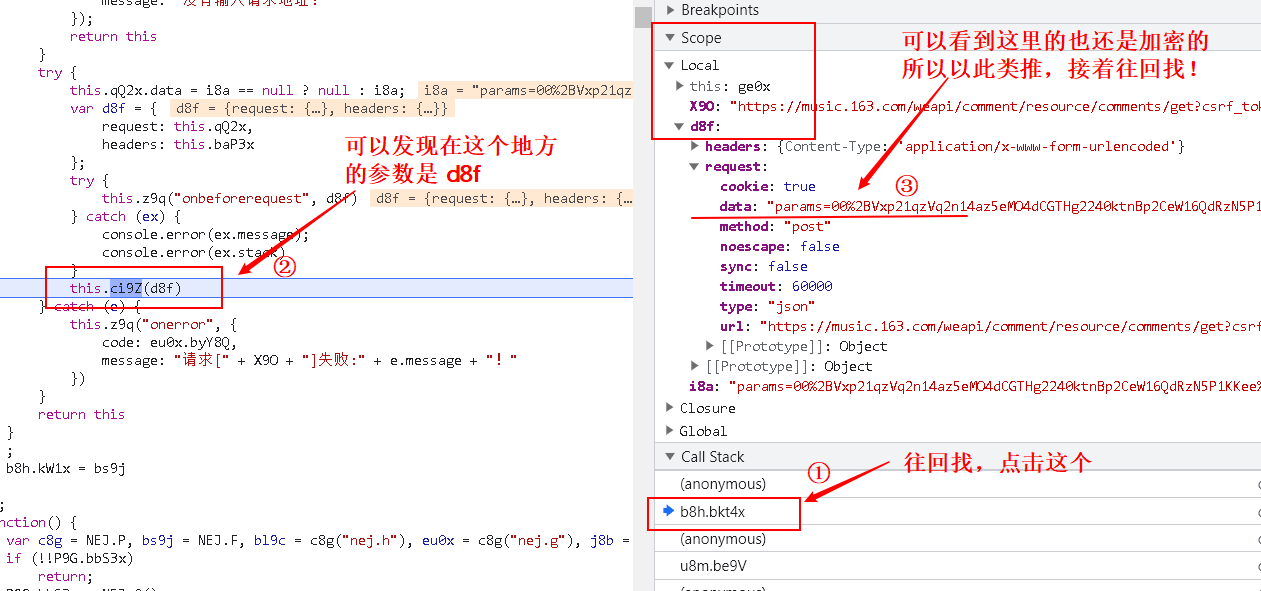
- 找到加密的函数,设断点,再进行分析
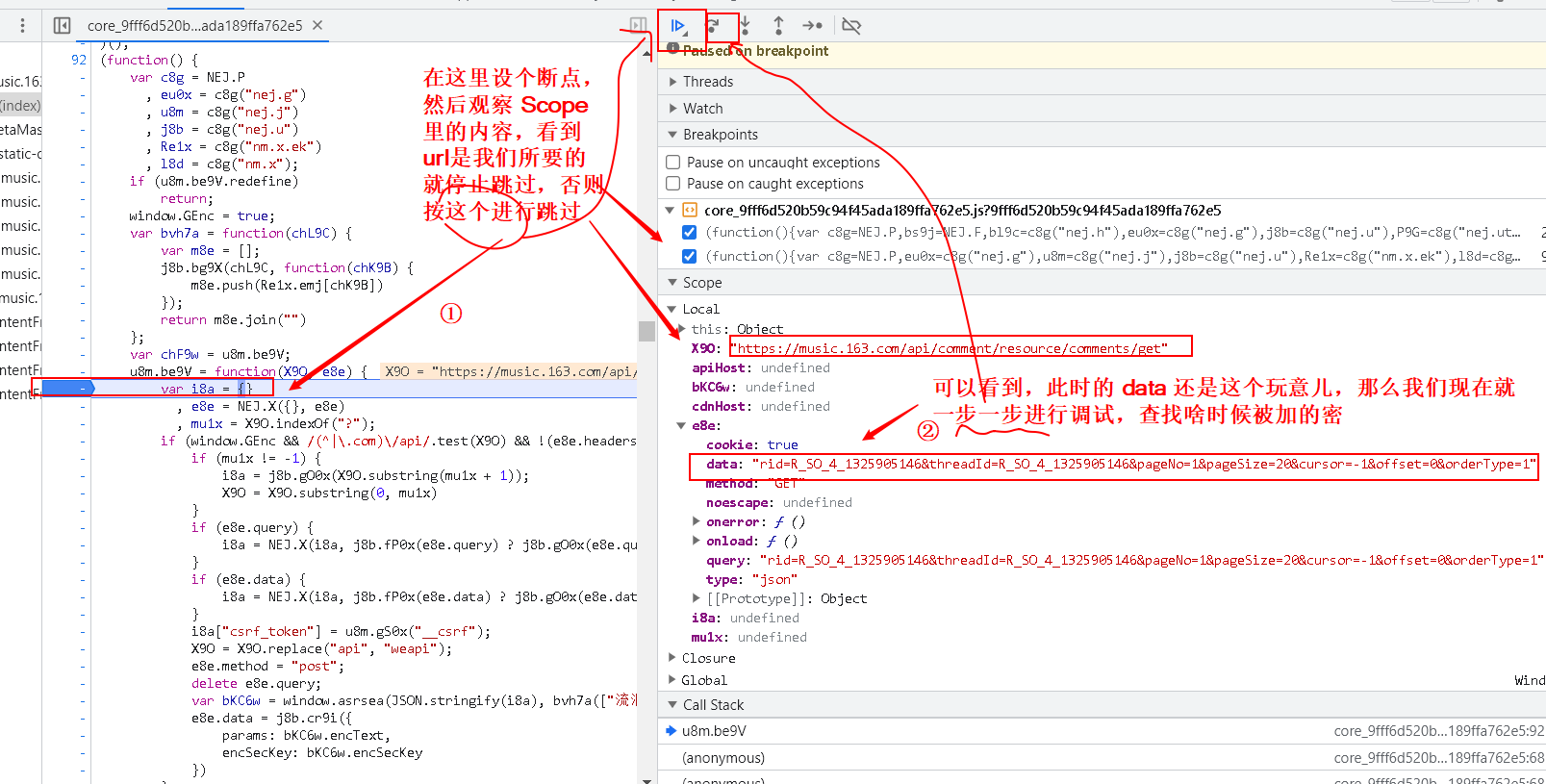
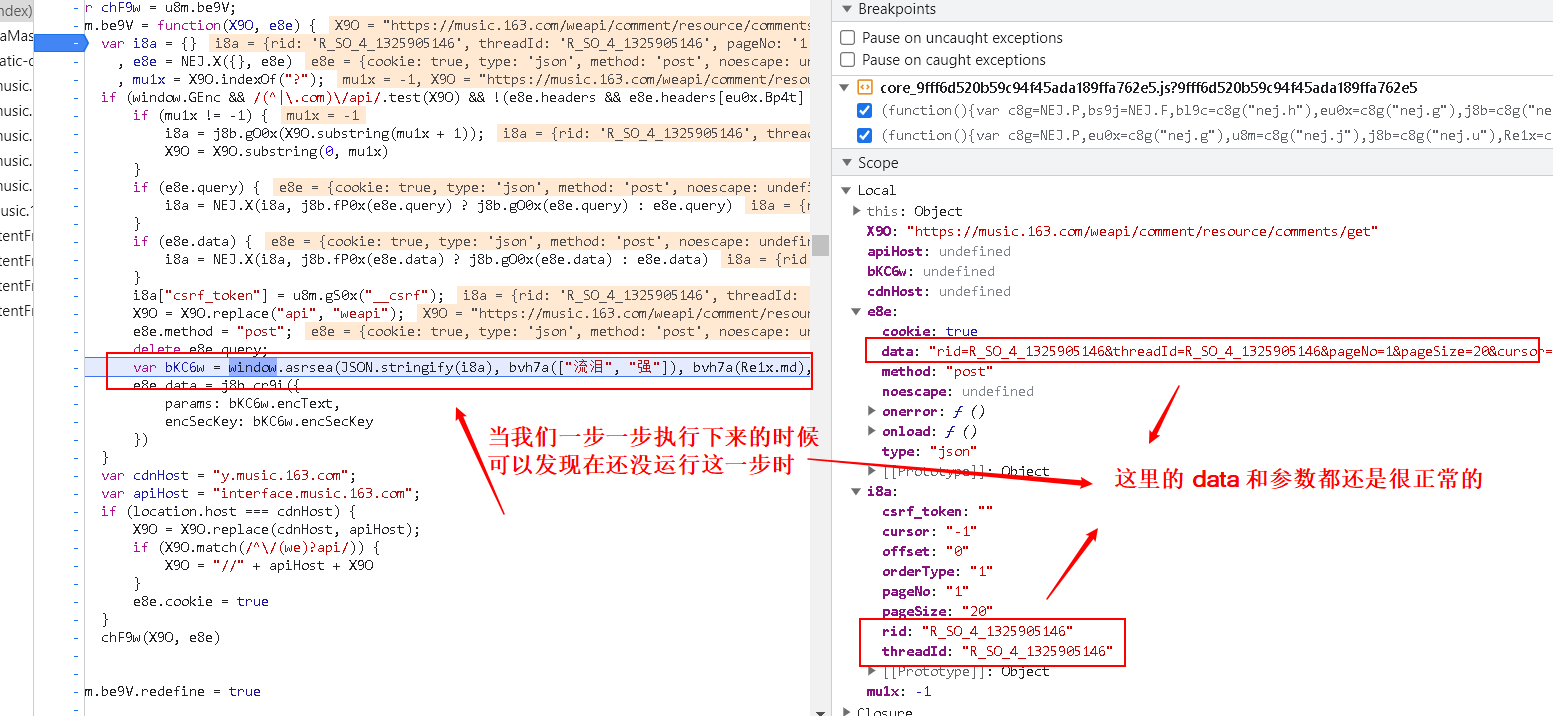
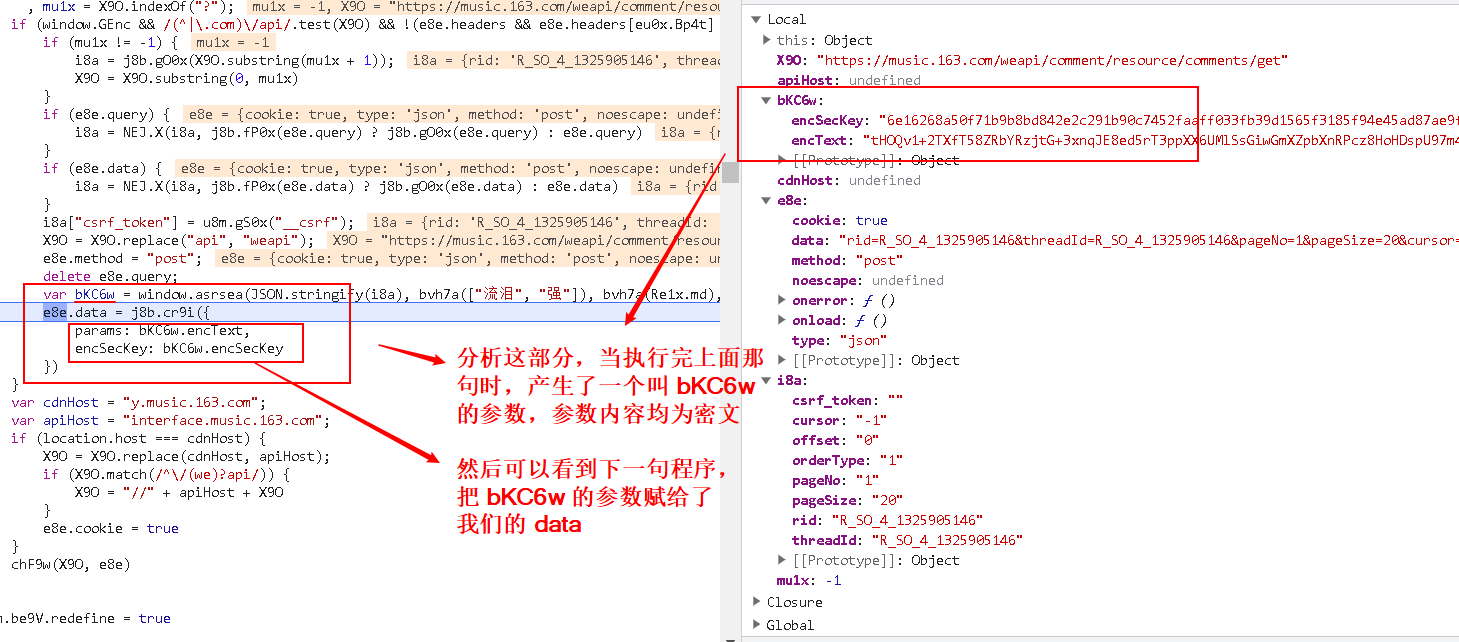
- 继续执行,验证猜想
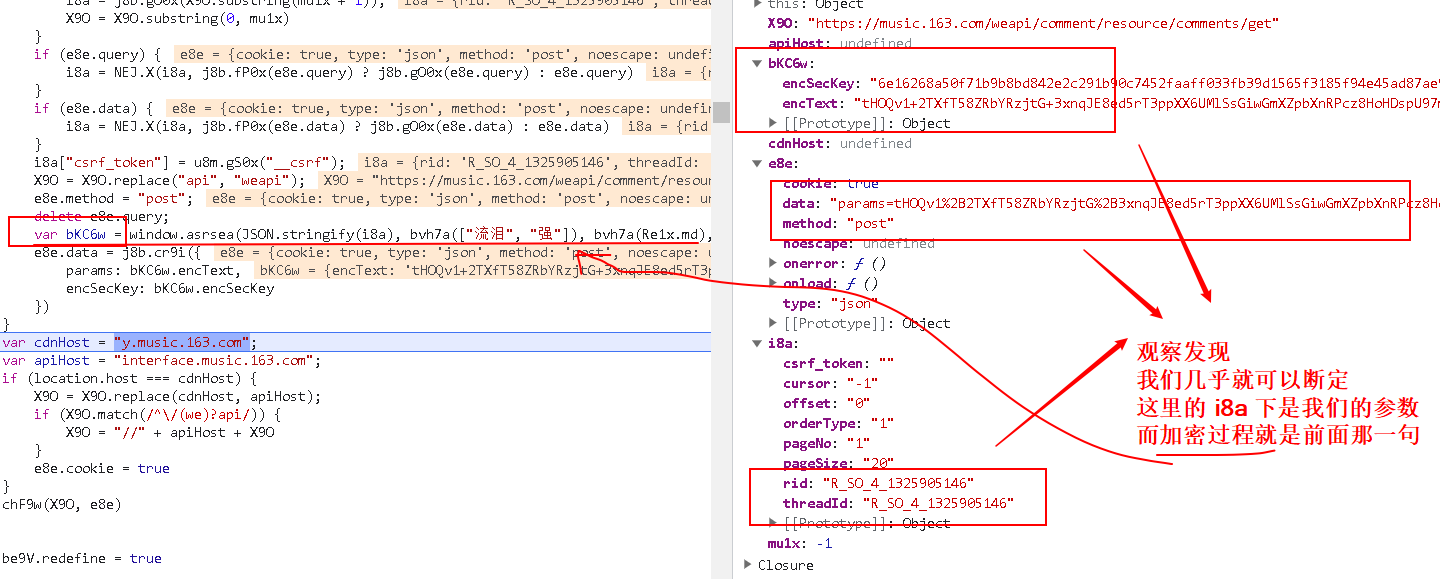
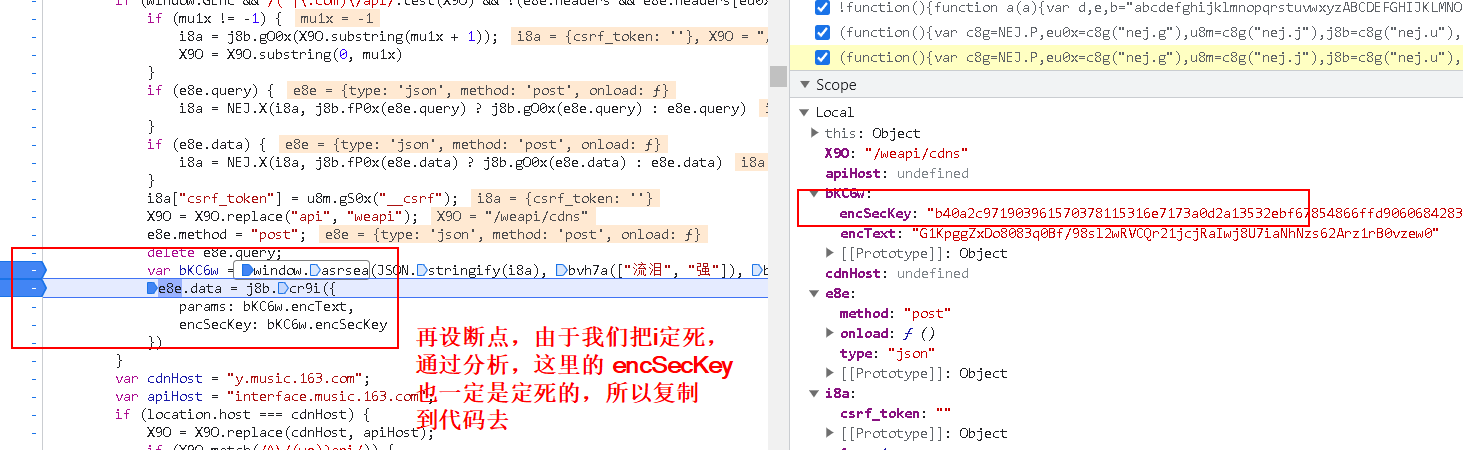
得出结论:
我们要的两个参数:
- params:encText
- encSecKey:encSecKey
都是由这个函数进行生成的:
var bKC6w = window.asrsea(JSON.stringify(i8a), bvh7a(["流泪", "强"]), bvh7a(Re1x.md), bvh7a(["爱心", "女孩", "惊恐", "大笑"]));
4.3 对加密过程进行分析
- 接下来分析下这个加密过程,直接
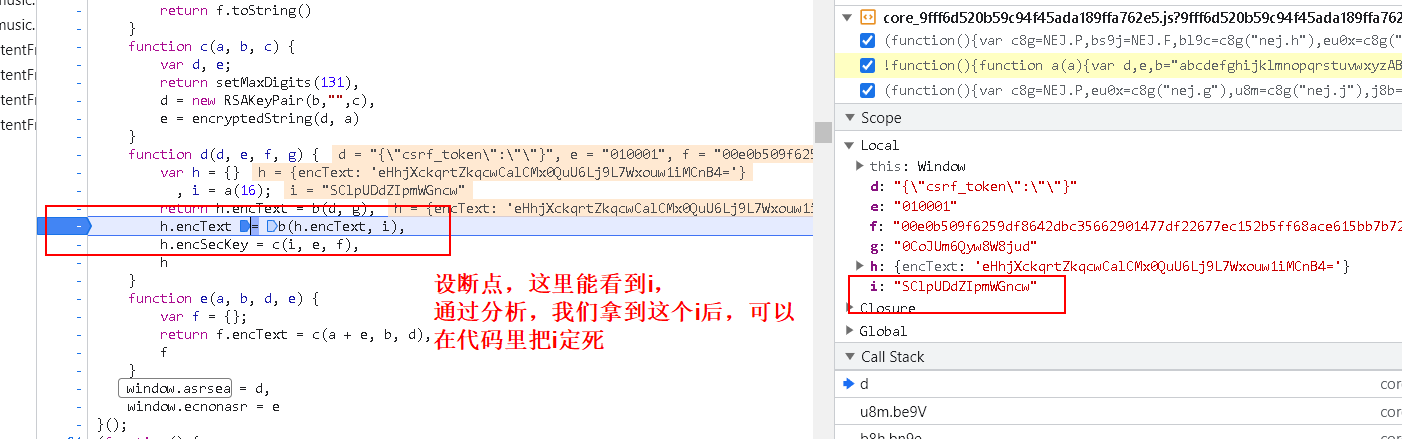
ctrl+f找下这个window.asrsea是啥?除了这句话之外,整个代码里只有下面这个地方有这个参数:window.asrsea = d
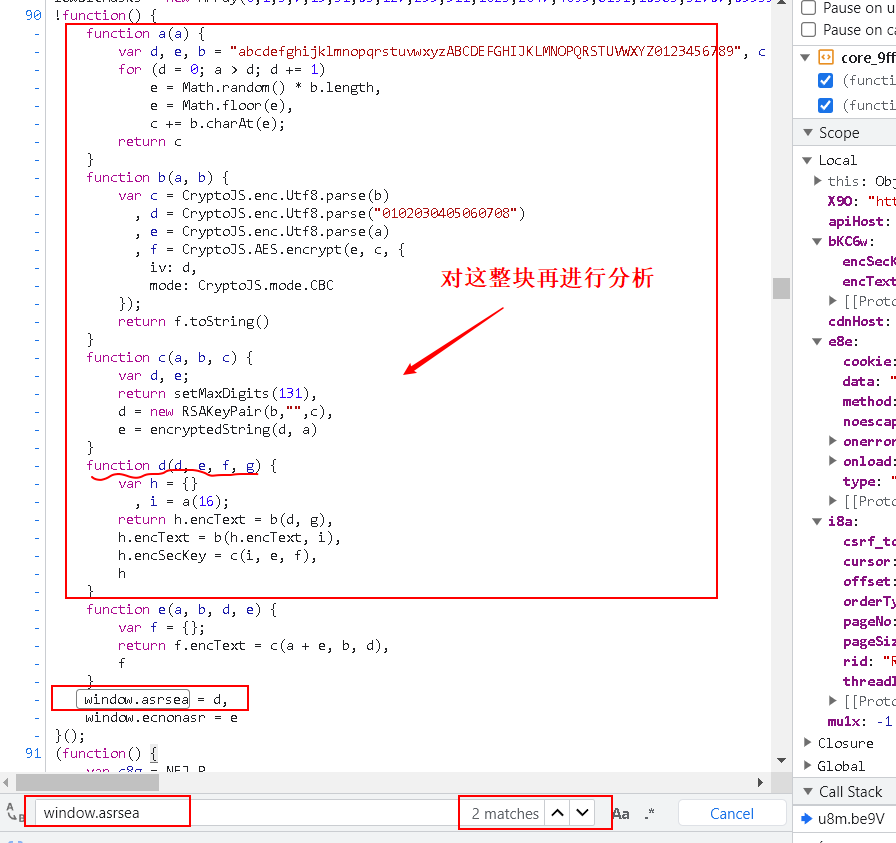
- 对 d 这个函数,结合加密语句进行分析
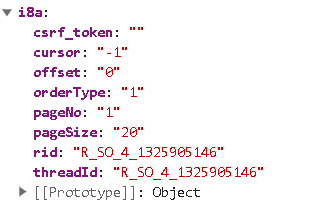
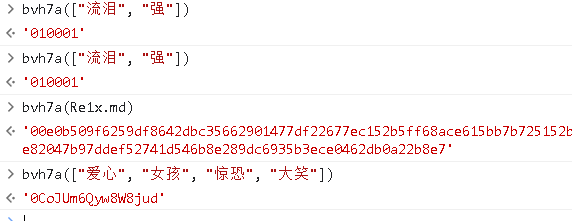
var bKC6w = window.asrsea(JSON.stringify(i8a), bvh7a(["流泪", "强"]), bvh7a(Re1x.md), bvh7a(["爱心", "女孩", "惊恐", "大笑"]));
1 | function d(d, e, f, g) { # d: 数据 e: 010001 f: 很长的一个定值 g: '0CoJUm6Qyw8W8jud' |
可以发现,参数的 d 就是数据,后面的我们可以通过 console.log 获取其内容
4.4 编写代码,得到结果
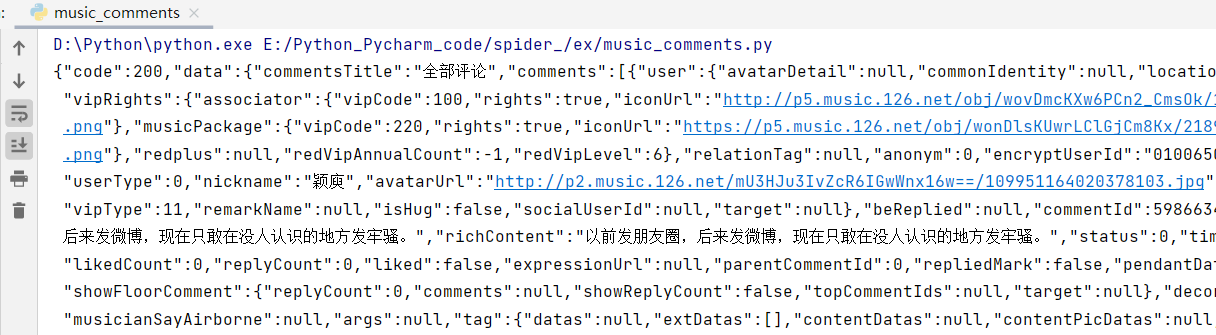
太厉害了这个,好难
1 | # 需求: |
- 结果,成功:
5. python 并发编程
5.1 简介
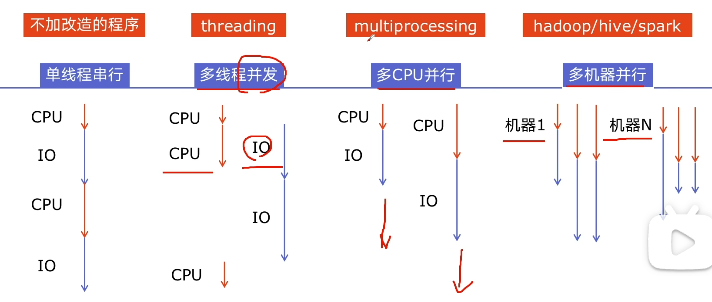
- 引入并发,就是为了提升程序的运行速度
- 程序提速的方法:
- 单线程串行:不加改造的程序
- 多线程并发:py 的 threading 模块
- 多 CPU 并行:multiprocessing
- 多机器并行:hadoop/hive/spark
- python 对并发编程的支持
- 多线程:threading,利用 CPU 和 IO 可以同时执行的原理,让 CPU 不会干巴巴等待 IO 完成
- 多进程:multiprocessing,利用多核 CPU 的能力,真正的并行执行任务
- 异步 IO:asyncio,在单线程利用 CPU 和 IO 同时执行的原理,实现函数异步执行
- 使用 Lock 对资源加锁,防止冲突访问
- 使用 Queue 实现不同线程/进程之间的数据通信,实现生产者(边爬取)-消费者(边解析)模式
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
- 使用 subprocess 启动外部程序的进程,并进行输入输出交互
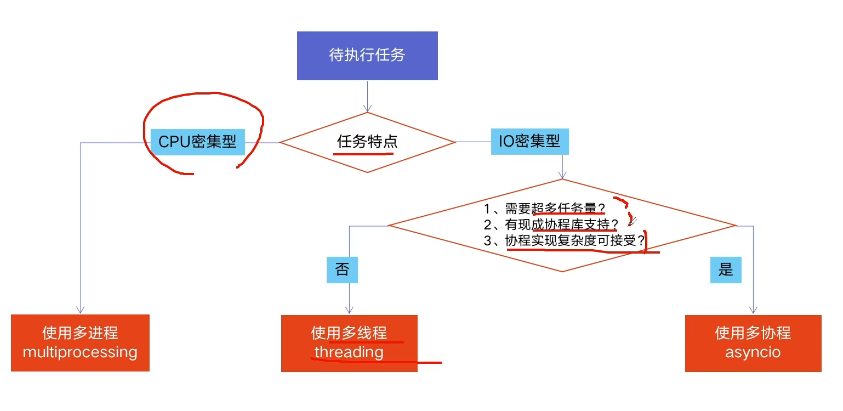
5.2 如何选择多线程多进程多协程
python 并发编程有三种方式:多线程 Thread、多进程 Process、多协程Coroutine
5.2.1 什么是 CPU 密集型计算、IO 密集型计算

5.2.2 多线程多进程多协程的对比

5.2.3 如何选择对应技术
- python 速度慢的原因:
- 动态类型语言,边解释边执行
- GIL(全局解释器锁),无法利用多核CPU并发执行
5.3 python 利用多线程加速爬虫
1 | import requests |
- 多线程
1 | import blog_spider |
5.4 实现生产者消费者模式的多线程爬虫
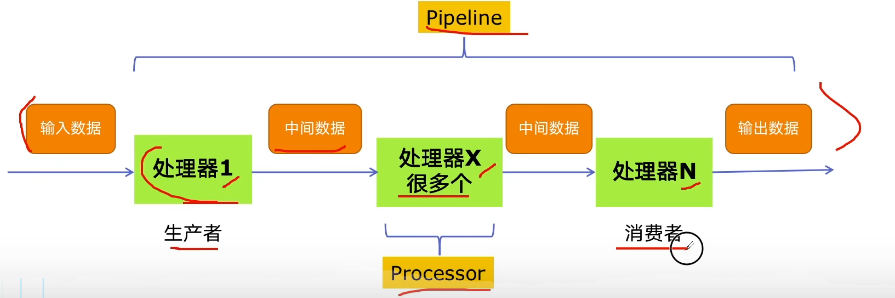
5.4.1 多组件的 Pipeline 技术架构
- 复杂的事情一般会分很多中间步骤一步步完成
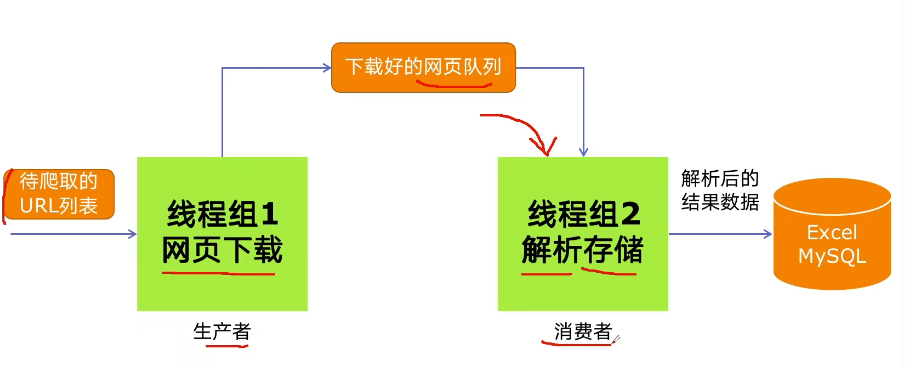
5.4.2 生产者消费者爬虫的架构
5.4.3 多线程数据通信的 queue.Queue
- queue.Queue 可以用于多线程之间的、线程安全的数据通信
1 | import queue |
5.5 线程安全问题以及 Lock 解决方案
线程安全:指某个函数、函数库在多线程环境中被调用时,能够正确的处理多个线程之间的共享变量,使程序功能正确完成
线程不安全:由于线程的执行随时会发生切换,造成不可预料的结果
Lock 用于解决线程安全问题:
lock = threading.Lock()- 用法一:
try-finally模式 - 用法二:
with模式
- 用法一:
代码示例:
- 错误示范:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import threading
import time
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name,
"取钱成功")
account.balance -= amount
print(threading.current_thread().name,
"余额: ", account.balance)
else:
print(threading.current_thread().name,
"取钱失败, 余额不足")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()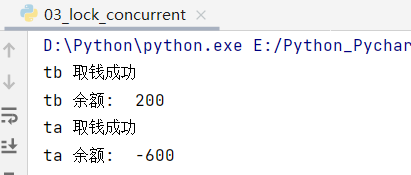
- 正确示范:加上 lock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name,
"取钱成功")
account.balance -= amount
print(threading.current_thread().name,
"余额: ", account.balance)
else:
print(threading.current_thread().name,
"取钱失败, 余额不足")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name="tb", target=draw, args=(account, 800))
ta.start()
tb.start()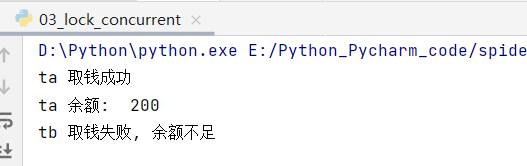
5.6 好用的线程池 ThreadPoolExecutor
- 线程池的原理:
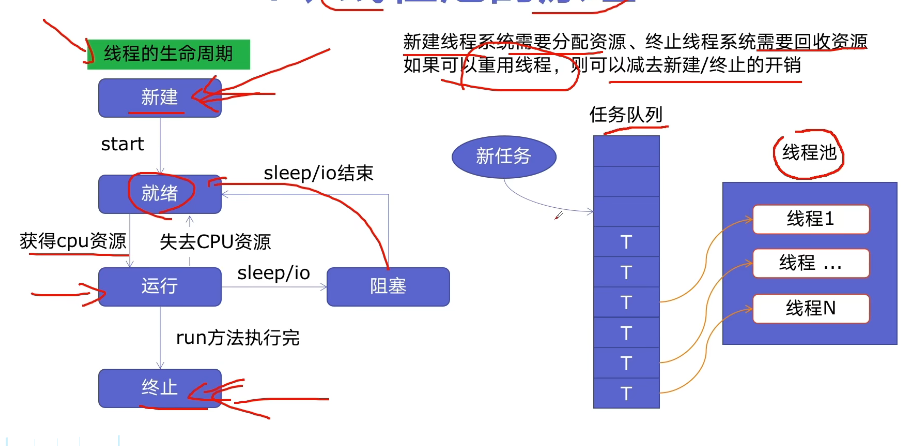
- 使用线程池的好处:
- 提升性能:减去大量新建、终止线程的开销,重用了线程资源
- 适用场景:适合处理突发性大量请求或需要大量线程完成任务,但实际任务处理时间较短
- 防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题